【RAGとは】仕組みや解決できる課題、活用例や精度の高め方

生成AIの普及が進む一方で「回答が古い」といった悩みを抱える企業が増えています。また、大規模言語モデルは幅広い質問に対応できますが、最新情報や組織内データの活用には限界があるといえるでしょう。
データ活用の課題を解決する策として使われるようになったのが「RAG(検索拡張生成)」です。
RAGという技術は、外部のデータベースから関連情報を検索し、回答の根拠として組み合わせる仕組みを指します。いわば「知識を持つ検索システム」と「文章を生成するAI」を一体化したイメージです。
本記事でRAGの基本的な考え方から仕組み、活用事例や導入時のポイントを詳しく見ていきましょう。
RAGとは

RAGとは、生成AIの精度と信頼性を高める技術です。
外部データを参照して回答を生成する仕組みにより、従来の生成AIが抱えていた限界を補えます。そのため、企業データベースや最新情報を反映した回答が可能となるでしょう。
本章では、RAGの基本概念から仕組み、活用例や導入時のポイントまでわかりやすく解説していきます。
従来のLLMとの違い
RAGと従来のLLMには、情報源の扱い方に根本的な違いがあります。従来のLLMは、あらかじめ学習したデータの範囲内でしか回答を生成できません。
一方、RAGは回答を生成する前に外部データベースを検索する工程を加えるため、参照できる情報の範囲を大きく広げられます。
<従来のLLMとRAGの主な違い>
| 比較項目 | 従来のLLM | RAG |
| 情報源 | 学習データのみ | 外部データ+学習データ |
| 最新情報対応 | 不可 | 可能 |
| ハルシネーション | 発生しやすい | 抑制しやすい |
たとえば、学習後に公開された最新ニュースや、随時更新される社内マニュアルといった情報にも対応が可能です。回答の正確性や信頼性が高まり、AIが事実と異なる内容を生成してしまう「ハルシネーション」のリスクも抑えやすくなります。
ファインチューニングとの違い
RAGとファインチューニングは、目的もアプローチも異なります。ファインチューニングは、モデル自体を追加学習によって調整する手法です。特定の話し方や、出力フォーマットに最適化したい場面で力を発揮します。
しかし、学習データの準備やモデルの再訓練には時間とコストがかかるでしょう。対してRAGは、モデルを変更せず、外部データベースを検索した結果を回答に組み込む構造です。
最新の社内情報や事実ベースの回答が求められる場面に適しているため、導入や運用のハードルも比較的低く抑えられます。
<ファインチューニングとRAGの主な違い>
| 項目 | 特徴 |
| ファインチューニング | 表現や形式の最適化に強い |
| RAG | 事実情報や最新データの反映に強い |
| コスト面 | RAGのほうが導入・運用負荷が低い |
用途に応じた使い分けが、重要といえるでしょう。
RAGが注目される背景
生成AIをビジネスで活用したいというニーズが高まる中、一般的なAIだけでは対応しきれない課題が浮き彫りになってきました。
学習済みモデルには企業固有の情報や最新データが含まれず、社内マニュアルや規程、非公開データも扱えません。結果として、誤情報が生成されるリスクやコンプライアンス上の懸念が実務利用の壁となっていました。
一方で、RAGは外部データベースを検索し、取得した情報を回答に反映する仕組みです。RAGは信頼性の高い情報をもとに回答が生成できるため、企業が安心して生成AIを活用する技術としての評価が高まっています。
【3つのフェーズ】RAGの仕組み

RAGはシンプルな構造でありながら、各工程の設計次第で性能が大きく変わります。検索精度が低ければ、後続工程の品質も下がってしまうでしょう。そのため、各フェーズの仕組みを正しく理解したうえでの最適化が重要です。
本章では、RAGの仕組みを以下3つの視点で紹介します。
- 検索
- 拡張
- 生成
上記を参考に、各フェーズの詳細を順番に見ていきましょう。
1.検索:Retrieval
検索フェーズは、RAG全体の精度を左右する工程です。ユーザーの質問をもとに外部の知識ベースやデータベースを検索し、回答に必要な情報を集めます。
集めた情報は、後のすべての工程に影響する重要な要素です。そのため、関係の薄いデータが混ざると、情報整理や回答生成の精度は下がってしまうでしょう。さらに、最終的な回答の質にも悪い影響が出てしまいます。
<検索フェーズで押さえるべきポイント>
- ユーザーの質問をもとに情報を取得
- 外部データから関連情報を抽出
- 検索精度が全体の品質を左右
RAG全体の性能を高めるためには、検索の設計をしっかり行いましょう。
2.拡張:Augmentation
拡張フェーズは、検索で得た情報をLLMが扱いやすい形に加工、最適化する工程です。
取得したデータをそのままLLMに渡すのではなく、質問文と組み合わせて指示文とともにプロンプトへ組み込む処理が行われます。
不要な情報を除外し、関連性の高い内容のみを反映すると、回答の精度と一貫性が向上するでしょう。
<拡張フェーズで対応すべき処理>
- 情報を要約しわかりやすくまとめる
- プロンプトテンプレートに組み込む
- 関連性の低い情報を除外する
プロンプト設計の質が最終的な出力結果に直接影響するため、拡張フェーズの作り込みはRAG全体の完成度を左右します。
3.生成:Generation
生成フェーズは、拡張されたプロンプトをもとにLLMが最終的な回答を出力する工程です。
外部から取得した情報と、モデルが持つ学習済みの知識を組み合わせると、より正確な回答を生成できます。
参照した情報源もあわせて提示できるため、回答の根拠をユーザーが確認しやすい点も特徴のひとつです。さらに、情報の透明性が高まり、意思決定の精度向上にもつながります。
<生成フェーズの特徴>
| 項目 | 内容 |
| 入力 | 質問+検索結果 |
| 処理 | LLMによる回答生成 |
| 特徴 | 外部情報を踏まえた出力 |
| メリット | 根拠の確認が可能 |
各フェーズの処理が適切に機能すれば、より信頼性の高い結果が得られます。
出典:NTT docomo Business Watch|RAG(検索拡張生成)とは
RAGを構成する主要コンポーネント6つ
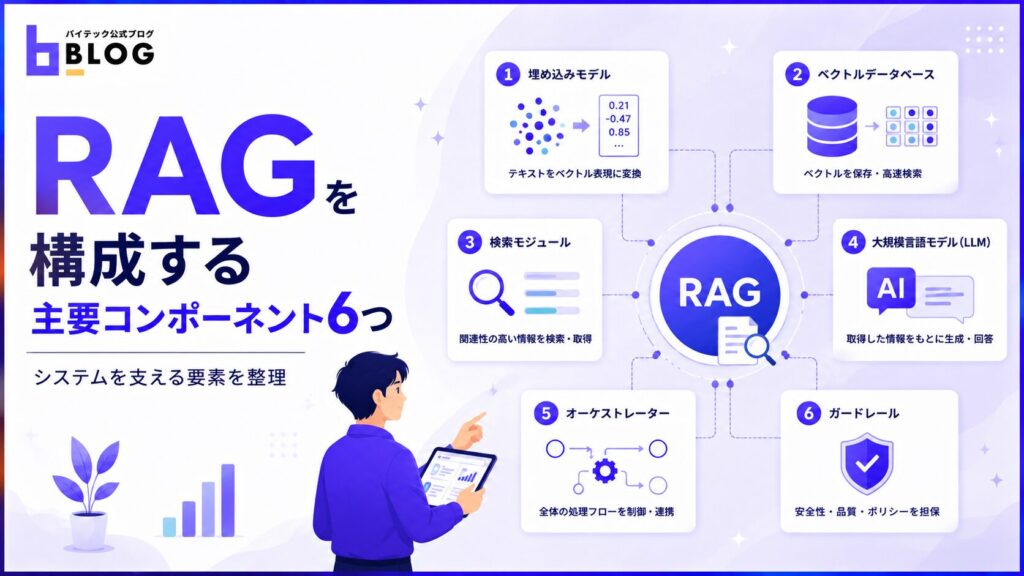
RAGは複数の技術要素が連携して動くため、各工程の設計によって性能が大きく変わります。
本章では、RAGを構成する主要な要素を以下6つの視点で紹介します。
- 埋め込みモデル
- ベクトルデータベース
- 検索モジュール
- 大規模言語モデル
- オーケストレーター
- ガードレール
上記の要素を順番に見ていきましょう。
埋め込みモデル(エンベディング)
埋め込みモデルは、文章や画像を数値(ベクトル)に変換する役割を持つ仕組みです。意味が近い内容ほど近い位置に配置されるため、単語が完全に一致しなくても関連情報を見つけられます。
一方で、埋め込みモデルの精度が低い場合、本来見つかるはずの情報を見逃す可能性があるでしょう。
<埋め込みモデルの特徴>
| 項目 | 内容 |
| 役割 | テキストや画像を数値データに変換 |
| 特徴 | 意味の近さで情報を探せる(単語一致に依存しない) |
| メリット | 表現が違っても関連情報を取得できる |
| 注意点 | 精度が低いと関連情報を見逃すリスクがある |
| 重要ポイント | 用途やデータに合ったモデル選定が必要 |
結果、RAG全体の精度にも影響が出るため、用途に合ったモデル選びが重要といえます。
ベクトルデータベース
ベクトルデータベースは、数値(ベクトル)に変換されたデータを効率的に保存し、類似度をもとに検索できる仕組みです。
コサイン類似度などの指標を活用するため、意味的に近い情報を大規模なデータの中から瞬時に見つけられます。単語の完全一致ではなく意味の近さで検索できるため、言い回しが異なる場合でも関連情報を取得できるでしょう。
<ベクトルデータベースの特徴>
| 項目 | 内容 |
| データ形式 | ベクトル(数値) |
| 検索方法 | 類似度ベース |
| 特徴 | 高速、大規模対応 |
| 役割 | 意味検索の実現 |
近年では従来型のデータベースにも同様の機能が追加され、既存の業務データとの統合も進んでいます。
検索モジュール(リトリーバー)
検索モジュールは、ユーザーの入力内容に対して最適な情報を抽出し、優先順位を決定する役割を担っています。
特に、キーワード検索とベクトル検索を併用する「ハイブリッド検索」の導入は非常に効果的です。単一の手法を用いるよりも、精度の高い検索結果が期待できます。
さらに「再ランク付け(Reranking)」機能を活用すれば、上位に表示される情報の関連性を一段と強化できるでしょう。複数のアプローチを適切に組み合わせると、抜け漏れを防ぎながら精度も高めやすくなります。
最終的な回答のクオリティは、検索モジュールの設計に大きく左右されるのです。用途やデータの特性を見極めた手法の選定に加え、細やかな調整を続けていきましょう。
大規模言語モデル(LLM)
LLMは、検索で集めた情報とユーザーの質問をもとに文章を組み立てる、RAGの中核となるパートです。
外部データを参照しながら回答を生成するため、既存モデルを活かしつつ、より正確で信頼できる内容に仕上がります。追加学習を行わなくても、最新情報や専門的な内容を反映できる点も特長です。
<LLMの主な役割>
- 検索結果と質問をもとに文章を生成
- 外部データを取り込みながら回答を構成
- 回答のわかりやすさや品質を左右
モデルを選ぶ際は、複数の観点を踏まえて判断する必要があります。
<選定時のチェックポイント>
- 一度に扱える情報量
- 文章の質
- コスト
- 応答速度
用途や利用シーンに応じた最適なモデル選びが、RAG活用の成果につながります。
オーケストレーター
オーケストレーターは、RAG全体の流れをまとめて管理する役割を担います。検索から回答生成までの一連の処理を、スムーズにつなぐために欠かせない存在です。
<オーケストレーターが担う主な処理>
- ユーザーからの質問受付
- 検索の実行
- プロンプトの組み立て
- 回答の生成
- 結果の返却
以上の工程を適切につなぐと処理は安定し、スピードも向上するでしょう。全体の流れを把握しやすくなるため、トラブル発生時の原因特定や改善にもつながります。
専用のフレームワークを活用すれば、構築の手間を減らしながら、実運用に適した設計へと整えやすくなるのです。
ガードレール
ガードレールとは、入力内容と出力結果の両面から不適切な情報が含まれていないかを検証する仕組みです。RAGシステムの、安全性と信頼性を確保する役割を担います。
有害な表現の検出や機密情報の漏洩防止といった機能を組み込むと、企業利用に伴うリスクを低減できるでしょう。さらに、利用ポリシーに沿った出力の管理や、想定外の回答を抑える仕組みとしても機能します。
バイアスの抑制や各種規制への対応にも関わるため、システムを実際の運用に移す段階では特に重要なパートです。生成AIを業務で活用する場面が増える中、ガードレールの設計はセキュリティ対策の観点からも欠かせない工程といえます。
RAGが解決する従来の生成AIの課題4つ
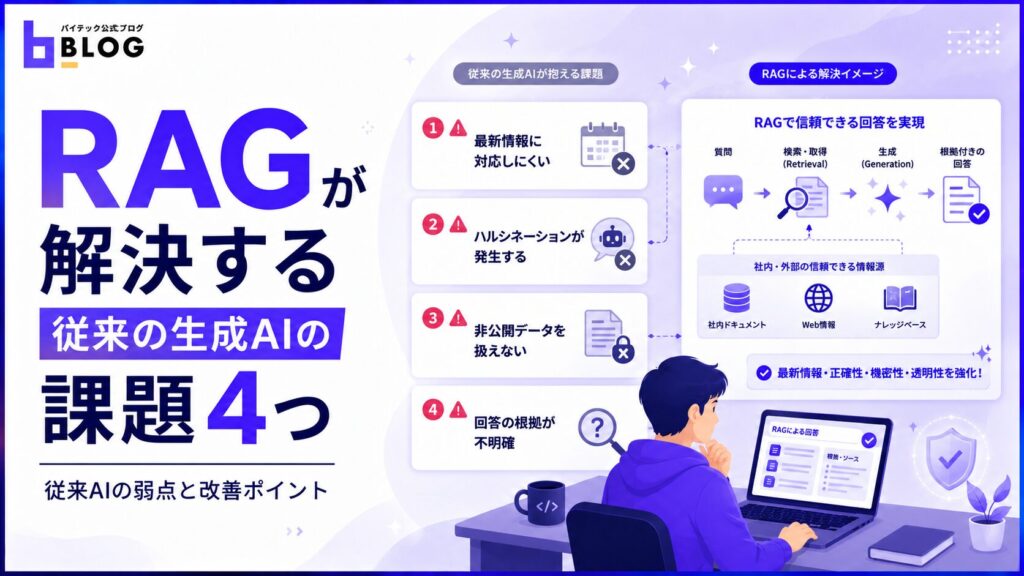
RAGは、生成AIをビジネスで活用する際に生じる代表的な課題を解消するための手法です。
本章では、RAGによって解消が期待される課題を以下4つの視点で紹介します。
- 学習データが古く最新情報に対応できない
- ハルシネーションが発生する
- 社内情報など非公開データを扱えない
- 回答の根拠や出典が不明確になる
上記を参考に見ていきましょう。
学習データが古く最新情報に対応できない
従来の生成AIモデルでは、学習後に発生した情報を反映するために、モデルの再学習が必要でした。
一方で、RAGは回答生成のたびに外部データを検索する仕組みを持つため、常に最新の情報をもとにした回答が可能です。法改正や市場動向、製品仕様の変更など時間とともに変化する情報にも、外部データベースを更新するだけで対応できます。
モデル自体に手を加える必要がないため、情報鮮度を維持するためのコストと運用負荷を大きく抑えられるでしょう。
特に情報の更新頻度が高い業界や、複数のデータソースを横断して扱う企業にとって、実務運用との相性が良い技術といえます。
ハルシネーションが発生する
従来の生成AIモデルは、あらかじめ学習したデータのパターンをもとに文章を生成する仕組みです。そのため、事実と異なる内容が混在するハルシネーションが課題でした。
RAGは実在するデータを根拠としてLLMに渡す構造を持ち、誤った内容が出力されるリスクを抑えられます。
事実ベースの情報を参照しながら回答を生成するため、根拠のない内容が含まれる可能性を低減できるでしょう。
<ハルシネーション対策のポイント>
- 実際のデータをもとにした回答
- 誤情報の発生リスクの低減
- リスト出力内容のチェック体制の整備
ただし、外部データ自体に誤りが含まれる場合や、検索精度が低い場合には誤情報が生じるリスクは残ります。RAGの導入と並行して、出力内容の検証プロセスの整備が重要です。
社内情報など非公開データを扱えない
従来の生成AIは公開情報をもとに学習しているため、会社ごとの情報を扱えず、実務とのズレが生じやすい状況でした。一方、RAGは社内ドキュメントや専用データベースをつないで、非公開データを参照できます。
モデルを再学習させる必要がなく、会社の実情に合った回答を出せる点が特長です。社内情報が扱えるようになると、問い合わせ対応や営業サポートへの活用が可能になるでしょう。
<活用できる情報の例>
- 業務マニュアル
- 契約情報
- 社内ルール
さらに、次のようなメリットも期待できます。
- 担当者の負担軽減
- 対応の質のばらつき抑制
- 情報更新への柔軟な対応
- 運用負担の軽減
回答の根拠・出典が不明確になる
業務に直結する情報を活用できる点が、RAGの大きな強みといえるでしょう。
従来の生成AIは、なぜ出力された回答に至ったのかが見えにくく、内容の正しさをユーザー自身が判断しづらい面がありました。一方、RAGは回答の根拠となる情報源をあわせて示せる仕組みになっています。
該当ドキュメントや参照箇所を明示すると、ユーザーが回答の内容を自分で確かめられるようになるでしょう。情報源が追跡できる状態になると、監査対応やコンプライアンス管理の場面でも活用しやすくなります。
さらに、意思決定の裏付けとしても活用できる点もポイントです。出力の根拠が明確になれば、業務利用における信頼性の向上に直結します。社内外への説明責任が求められる場面でも、RAGの透明性は大きな強みとなるでしょう。
RAGの代表的な活用例5選
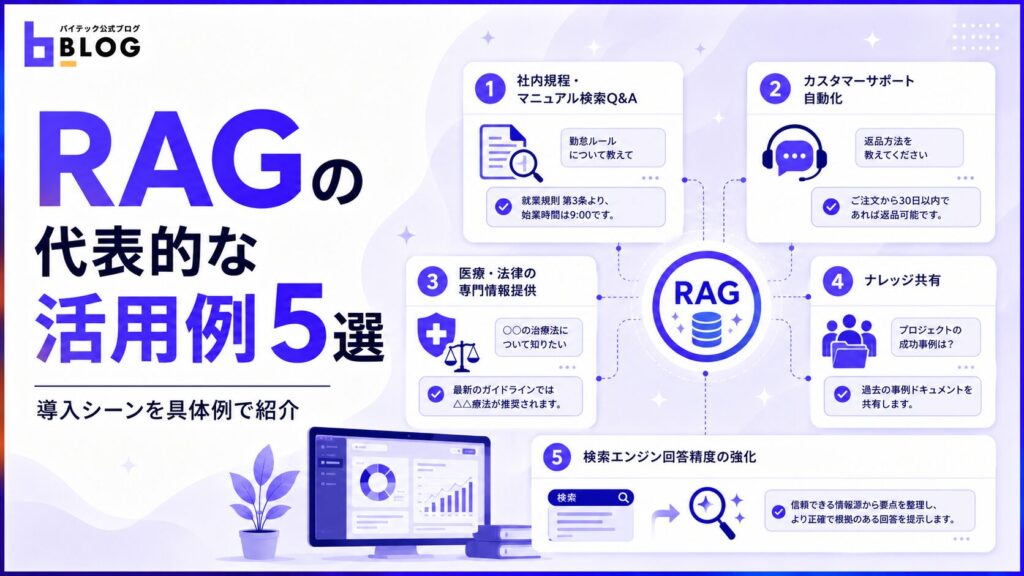
RAGは社内情報の検索や顧客対応の自動化など、幅広い業務で活用が進んでいます。外部データを参照しながら回答を生成できるため、従来の検索やFAQよりも精度の高い情報を届けられるのです。
業務効率の改善と情報活用の高度化を同時に進められる点が、多くの企業から評価されているでしょう。本章では、RAGの具体的な活用例を紹介します。
社内規程・マニュアルの検索と質問応答
社内規程や業務手順をデータソースとして登録すると、従業員からの自然な質問に対して即時に回答できる仕組みを整えられます。
<社内情報として活用できる主なデータ>
- 就業ルール
- 経費処理
- 福利厚生の手続き
日常的に参照される情報へすぐにアクセスでき、管理部門への問い合わせ件数を減らせるでしょう。回答とあわせて参照元の文書も提示されるため、内容の正確性をその場で確認できます。
また、担当者が不在の時間帯でも一定水準の回答が得られるため、対応の遅れも防ぎやすいです。従業員が必要な情報へアクセスできるようになると、業務のスピード向上や自己解決率の改善も期待できます。
カスタマーサポートの自動化・効率化
FAQやサポート情報をデータソースとして活用すれば、顧客からの問い合わせに対して自動で回答できる体制を整えられます。製品情報や過去の対応履歴を参照しながら回答を生成するため、問い合わせ内容に応じた適切な返答が可能です。
<カスタマーサポートにおける主なメリット>
- 自動応答による対応速度の向上
- オペレーターへの依存を軽減
- エスカレーションとの併用が可能
複雑な案件や判断が難しいケースは、担当者へ引き継ぐ運用と組み合わせましょう。品質を維持しながら対応効率を高められ、顧客の待ち時間短縮とサービス満足度の向上につながります。
医療・法律分野での専門情報の提供
RAGは、高い正確性が求められる専門分野でも有効です。外部の専門データを参照しながら回答を生成できるため、情報の信頼性を担保しやすくなります。
<分野別の活用例>
| 分野 | 活用内容 |
| 医療 | 診療指針や最新の研究データに基づく情報の提示 |
| 法律 | 法令や判例を参照した根拠のある情報の提示 |
| 金融 | 規制情報や市場データを活用したリスク管理や投資判断に役立つ情報の提示 |
参照した出典情報もあわせて示されるため、専門家が内容を確認しながら安心して活用できます。情報の透明性が高い点は、専門性が求められる業務において特に重要な特徴といえるでしょう。
ナレッジマネジメントと社内情報共有
RAGは、企業内の情報をより活用しやすくします。なぜなら、蓄積されたドキュメントやノウハウを、横断的に検索できるためです。
たとえば、過去事例の参照や技術情報の共有を効率化できます。従来は手作業で行っていた情報収集も大幅に短縮され、必要な情報へすぐにたどり着けるようになるでしょう。検索にかかる時間が減ると、より重要な業務に集中できる環境も整います。
結果として、新入社員の立ち上がり支援や部門間連携の強化につながるのです。さらに、属人化していた知識の共有も進みます。
また、常に最新の情報を反映できる点もメリットです。意思決定のスピード向上にもつながるでしょう。
検索エンジンの回答精度の強化
RAGは、検索をより使いやすくします。複数の情報源をまとめて扱い、自然な言語で回答を表示しやすくなるためです。
たとえば、従来のように検索結果のリンク一覧を確認するのではなく、必要な情報が整理された形で表示されます。
<従来の検索とRAGの違い>
| 項目 | 従来検索 | RAG活用 |
| 検索方法 | キーワード一致中心 | 意味理解ベース |
| 表示形式 | リンク一覧を表示 | 回答を直接提示 |
| 情報取得 | 情報収集に時間がかかる | 即時に要点を取得できる |
ユーザーは情報を一つひとつ探す手間を省けるため、短時間で要点を把握できるでしょう。結果として、判断にかかる時間も短縮され、意思決定のスピード向上につながります。また、検索精度が高まれば、必要な情報へ迷わずたどり着ける点も大きな利点です。
RAGの精度を高める5つのポイント

RAGは検索やデータ処理、プロンプト設計など複数の要素が絡み合うため、設計次第で回答品質が大きく変わります。
検索方式やデータの分割方法が異なるだけで、結果に大きな差が生じるケースも少なくありません。本章では、実務で押さえておきたい改善のポイントを紹介します。
検索方法を目的に応じて使い分ける
検索方式の選び方は、RAGの回答精度に大きく影響する重要なポイントです。検索方法ごとに得意な質問や扱いやすいデータの特徴が異なるため、目的に合った方式を選ぶ必要があります。
単語の一致を重視する場合は、キーワード検索が適しているでしょう。一方で、質問の意味を踏まえて関連情報を探したい場合はベクトル検索が向いています。すなわち、両方を組み合わせたハイブリッド検索を使えば、さまざまな質問に対応しやすくなるのです。
<検索方式ごとの特徴>
| 検索方式 | 特徴 |
| キーワード検索 | 単語の一致に強い |
| ベクトル検索 | 意味の理解に強い |
| ハイブリッド検索 | 両者の利点を統合 |
用途やデータの特性に応じて検索方式を使い分けると、より関連性の高い情報を安定して取得しやすくなるでしょう。
チャンク分割の単位とサイズを最適化する
チャンク設計とは、外部データをどの単位で分割して保存するかを決める工程です。分割の仕方によって文脈の保持量とノイズの多さが変わるため、検索精度に大きく影響します。
チャンクサイズが大きすぎると不要な情報が混ざりやすく、小さすぎると意味のつながりが途切れてしまうでしょう。分割方法には、固定長で均等に区切る方法と、文章の区切りや段落に合わせて柔軟に分割する可変長の方法があります。
それぞれ得意なデータの種類が異なるため、扱う文書の特性に応じて使い分けが大切です。
また、文書の構造に合わせた適切なサイズ設計が、安定した検索精度を保つうえで重要といえるでしょう。加えて、チャンク同士を一部重複させるオーバーラップ設定の細かい調整も、精度向上に効果的です。
ハイブリッド検索+セマンティックランク付けを導入する
検索結果の再評価とは、最初に取得した候補を対象に意味の近さをもとに順位を見直す処理です。検索精度をさらに高めるための、重要な工程といえるでしょう。
ハイブリッド検索で抽出した候補にスコアを付けて並べ替えると、より関連性の高い情報を上位に表示できます。実際の検証でも、幅広いクエリに対して高い精度が確認されました。検索とランク付けを組み合わせた場合、個々のクエリに対する回答品質を底上げできます。
特に、質問の表現が曖昧な場合や複数の意味に解釈できるケースでも、適切な情報を優先して表示しやすくなるでしょう。
プロンプト設計を継続的に改善する
プロンプトの質は、出力結果に大きく影響します。大規模言語モデル(LLM)は与えられた指示に沿って回答を作るため、指示の内容によって答えの方向性が変わってしまうのです。
たとえば、参照する情報の範囲を限定する指示を加えると、誤った情報が含まれるリスクを抑えやすくなります。あわせて、情報の見せ方や指示文の書き方も重要なポイントです。
曖昧な指示では意図と異なる回答が返ってくる場合があるため、具体的でわかりやすい表現を心がける必要があります。さらに、目的に応じて指示の細かさを調整する工夫も重要です。
結果として、ユーザーの質問傾向やフィードバックを踏まえながら、継続的に改善していく姿勢が求められます。
評価指標を設定して定期的にチューニングする
RAGは、評価と改善を繰り返すことで精度が高まります。品質を数値で把握しないと、改善の効果を正しく捉えにくくなるためです。
たとえば、一貫性や根拠性、文章の自然さといった基準に沿って回答をチェックします。あらかじめ評価基準をそろえておけば、結果のばらつきを防ぎやすくなるのです。評価結果をもとに検索設定やデータ構造を見直すと、段階的に改善が進められます。
<評価項目一覧>
| 評価項目 | 内容 |
| 一貫性 | 回答の整合性 |
| 根拠性 | 情報の信頼度 |
| 流暢さ | 文章の自然さ |
さらに、改善内容を記録しながら運用すると、再現性のある調整がしやすくなるでしょう。定期的な見直しにより、安定した品質が維持できます。
RAGの限界と導入時の注意点4つ
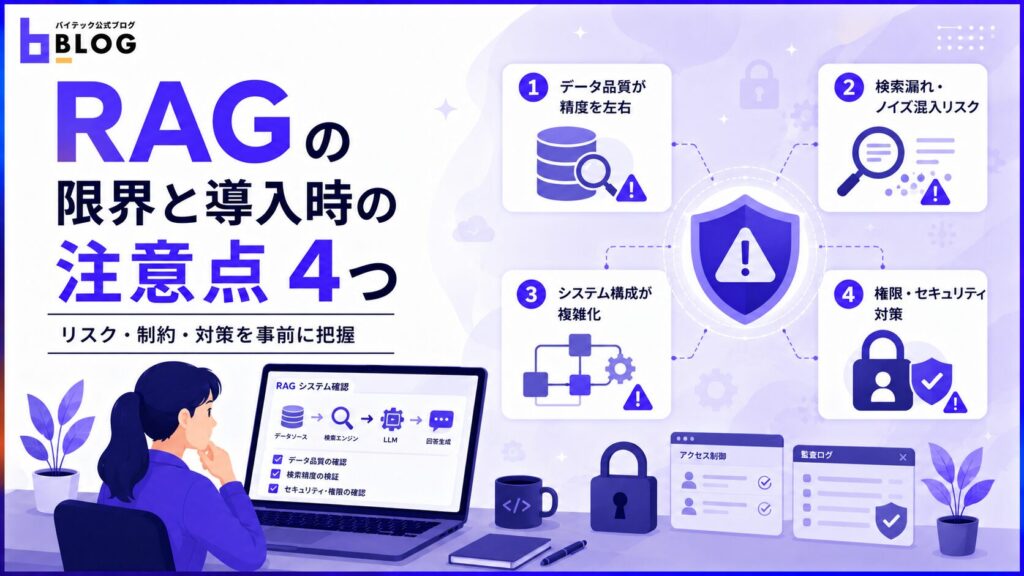
RAGは多くの課題を解消できる一方で、導入時には注意すべきポイントもあります。外部データや複数の仕組みで動くため、品質や運用面で新たな課題が生じてしまうのです。
本章では、RAG導入時に押さえておきたい注意点を以下の視点で紹介します。
- データ品質の管理
- 検索精度の確保
- セキュリティ対策
- 運用体制の整備
上記を参考に見ていきましょう。
知識ベースのデータ品質に精度が左右される
RAGの性能は、データ品質に大きく左右されます。回答の根拠となる情報が、外部データにあるためです。
誤った内容や曖昧な記述が含まれていると、出力結果にもそのまま影響が出てしまいます。矛盾した情報が混在している場合には、一貫性のない回答につながる可能性もあるでしょう。
さらに、必要な情報が登録されていなければ検索自体が成り立ちません。データの更新が遅れると、古い情報が使われてしまうリスクもあります。情報の詳細度がそろっていない場合も、検索精度の低下につながるでしょう。結果として、正確性や統一性を保つためには、データの整備と見直しを継続的に行う必要があります。
検索の取りこぼし・ノイズ混入のリスクがある
検索精度のばらつきは、大きな課題となります。関連する情報を見逃したり、関係のない情報を拾ってしまう可能性があるためです。
たとえば、表現の違いによって文書が見つからない場合や、同じキーワードでも文脈の異なる情報が混ざるケースが考えられます。取得した内容が適切でないと、回答も的外れになってしまうでしょう。
<検索精度に関する主な課題>
- 関連情報の取りこぼし
- 無関係な情報の混入
- 検索方式の最適化
検索結果の質がそのまま回答の質に影響するため、安定した精度を保つ工夫が欠かせません。検索方式の選び方や組み合わせ方によって結果が変わるため、用途に応じた設計も重要です。
システム構成が複雑になりやすい
RAGは、システム運用が複雑になりやすい傾向があります。複数の仕組みが組み合わさって動くため、全体を見ながら管理しなければなりません。
ひとつの変更が全体に影響する場合もあり、慎重な運用が求められるでしょう。運用体制や担当者のスキルも、重要な要素となります。導入する際は、あらかじめルールを整えておくと安心です。
<運用面での主な課題>
- 複数機能の連携管理
- バージョン管理や互換性の維持
- トラブル発生時の原因特定
上記の課題に対応するためには、小規模で導入して段階的に広げていく進め方や、管理機能が整ったサービスを活用しましょう。
閲覧権限やセキュリティの考慮が不可欠になる
RAGの導入時には、セキュリティ対策は欠かせません。社内データを扱う場合には、情報漏洩のリスクが伴うためです。
たとえば、権限管理が不十分だと、本来は閲覧できない情報が回答に含まれてしまう可能性があります。さらに、外部サービスへデータを送る際のリスクにも注意が必要です。
<主なセキュリティリスクと対策>
| リスク項目 | 内容 |
| データ漏洩 | 機密情報が外部に出てしまう可能性 |
| 権限管理 | 不適切なアクセスが発生するリスク |
| 外部送信 | データの利用範囲を適切に管理する必要 |
| 対策 | 複数の観点からのセキュリティ設計 |
データの取り扱いルールを明確にしておかないと、思わぬトラブルにつながる場合もあるでしょう。アクセス制御やデータ保護、利用範囲の制限などを組み合わせた対策が求められます。
【FAQ】RAGに関するよくある質問

RAGに関する疑問は、導入検討時に多く生じやすい傾向にあります。技術理解だけでなく、実務活用や運用面の判断も求められます。
そのため、あらかじめ疑問を明確にしておくと導入判断もしやすくなるでしょう。本章ではRAGに関するよくある質問を取り上げ、RAG導入検討時に重要なポイントをわかりやすく解説します。
RAGとは何ですか?
RAGとは、下記3つの工程を組み合わせた技術で「ラグ」と読むのが一般的です。
従来の生成AIが学習済みデータのみをもとに回答するのに対し、RAGは外部情報をリアルタイムで参照できます。
<RAGを構成する主な工程>
| 用語 | 意味 | 役割 |
| Retrieva | 検索 | 外部データベースから関連情報を取得する |
| Augmented | 拡張 | 取得した情報をプロンプトに組み込む |
| Generation | 生成 | 組み込んだ情報をもとに回答を生成する |
生成AIのビジネス活用が広がる中、RAGはAIシステムを理解するうえで欠かせない基礎知識として定着しつつあるのです。技術的な背景を知らなくても、仕組みの概要を把握しておくと、導入検討や社内での議論がスムーズに進むでしょう。
RAGを使うメリットは何ですか?
RAGは、実務での活用に適した多くのメリットがあります。外部データを参照しながら回答を生成する仕組みにより、従来の生成AIが抱えていた弱点を補えるのです。
<RAGの主なメリット>
- 再学習なしで最新情報を反映
- 誤情報の発生リスクを低減
- 非公開データの活用が可能
- 出典提示による透明性向上
- 幅広い業務への適用
社内の非公開データを扱え、そのうえ回答と合わせて出典を表示できる点も、ビジネス利用において重要な強みといえるでしょう。状況に応じて柔軟に情報を取り込める構造のため、幅広い業務に適用しやすいです。また、安定した運用と柔軟な対応の両方を実現できます。
RAGを導入するにはどうすればいいですか?
RAGの導入には「データ」「技術」「運用」の3つの準備が必要です。RAGは複数の仕組みを組み合わせて動くため、事前に全体の方針を確認しておきましょう。準備が不十分なまま進めると、導入後に精度や運用面で課題が生じやすくなります。
関係者間での、目的や役割の共有が大切です。加えて、運用ルールや責任範囲も明確にしておくと良いでしょう。
<導入前に準備すべき主な項目>
- 社内データの整備
- 基盤となる技術の選定
- 検索方式やプロンプトの設計
- 評価基準の設定
導入前は準備すべき項目を確認しながら効果を図り、徐々に適用範囲を広げていく進め方が有効です。
RAGでハルシネーションは完全になくなりますか?
RAGでも、ハルシネーションを完全には防げません。LLMが情報を誤って解釈する可能性や、検索結果の質に影響されるためです。関連性の低い情報が取得された場合、誤った回答が生成されるケースもあります。
RAGはリスクを抑える仕組みとして有効ですが、RAGの導入だけでは万全とはいえません。そのため、出力内容をチェックする仕組みや人の目による確認が重要です。
さらに、検索精度の改善やデータ品質の見直しを継続的に行うと、誤情報の発生を抑えやすくなるでしょう。運用ルールを整え、どの段階で確認を行うかを明確にしておく点も欠かせません。結果として、精度と安全性のバランスを保ちながら活用しやすくなります。
エージェント型RAGとは何ですか?
エージェント型RAGは、AIが自律的に判断しながら検索や処理を進める、より高度な仕組みです。
通常のRAGが決まった手順で処理を進めるのに対し、エージェント型は状況に応じて柔軟に動作を変えられます。複数のデータソースを横断して必要な情報を集めたり、得られた結果をもとに処理の内容を見直したりできるのが特徴です。
役割の異なるエージェントを組み合わせると、複雑な業務や高度な判断が求められるタスクにも対応しやすくなるでしょう。
一方で仕組みが複雑になる反面、設計や管理の難易度は上がります。処理の流れが見えにくくなるケースもあり、運用面での工夫が必要です。処理量が増えるとコストにも影響が出るため、導入する際は目的と期待効果を見極める必要があります。
まとめ
RAGは生成AIの弱点を補い、実務での活用を支える重要な技術です。「検索」「拡張」「生成」といった仕組みにより、最新情報や社内データを反映した回答が可能になります。
従来の生成AIでは難しかった、情報の鮮度や根拠の明確さを高められる点が大きな特長です。
また、運用面の設計も欠かせません。導入後の管理や改善を怠ると、期待した効果が得られない場合もあります。
必要な仕組みやツールの選び方と改善の積み重ねにより、回答の信頼性と業務効率を両立できるでしょう。段階的に導入と検証を重ねながら自社に合った形で活用していくのが、RAG導入成功のポイントです。


