【LLMとは】基本的な仕組みや種類、実現可能なタスクをわかりやすく紹介

「LLM」という言葉を耳にする機会は増えたものの、正確に説明できる方はまだ少ないのではないでしょうか。
LLMとは、膨大なテキストデータをディープラーニングで学習し、人間のように自然な文章を理解・生成できるAI技術です。ChatGPTやGeminiといったAIサービスの中核を担っており、文章作成・翻訳・コード生成など幅広い業務に活用されています。
本記事では、LLMの基本的な仕組みや種類から、活用できる場面・注意点まで、AI初心者の方にもわかりやすく解説します。
そもそも「LLM」とは

LLM(大規模言語モデル:Large Language Model)とは、膨大なテキストデータをディープラーニング(深層学習)で学習させたAIモデルです。インターネット上の書籍や論文などからデータを収集します。
従来のAIに比べ「データ量」「計算量」「パラメータ数」が圧倒的に大きいため、人間のような自然な文章理解・生成が可能です。ChatGPTやGeminiなどの中核技術としてLLMが使われています。
まずは、LLMの基本的な仕組みや生成AIとの違いを見ていきましょう。
LLMの仕組み
LLMは、大量のテキストデータから「ある単語の後にどの単語が続きやすい」という確率のパターンを学習して予測・モデル化する技術です。
現在、ほとんどのLLMに「Transformer(トランスフォーマー)」と呼ばれるディープラーニングのアーキテクチャ(仕組み)が利用されています。2017年にGoogleが論文『Attention Is All You Need』で発表した技術です。
Transformerには、文中の全単語の関係性を同時に把握・反映できるセルフアテンション(自己注意機構)という仕組みがあります。過去のモデルが文章を順番に処理していたのに対し、Transformerは文全体を同時処理できるため、文脈の自然な応答が可能なのです。
出典:Google|Attention Is All You Need (v7)
LLMが注目される理由
LLMが注目される理由は、従来のAIをはるかに上回る自然な応答能力と、専門知識がなくても使いやすい手軽さにあります。
従来のチャットボットは、既定のルールに沿って回答する仕組みのため、想定外の質問には対応できませんでした。
対して、LLMはディープラーニングで膨大なデータから言語パターンを学習しているため、あいまいな質問にも柔軟に回答できます。
さらに、2022年末に登場したChatGPTの普及により、初心者でも高度なAIを扱えるようになりました。一つのモデルで文章生成・翻訳・コード生成など複数のタスクを行える点も人気です。
現在では教育・医療・ビジネスなどさまざまな分野への導入が加速し、注目が高まっています。
LLMと生成AIの違い
LLMと生成AIは混同されがちですが、両者の関係は「全体と部分」だといえるでしょう。
主な違いは以下の通りです。
<生成AIとLLMの違い>
| 用語 | 扱えるデータ | 主な用途 |
| 生成AI | ・テキスト ・画像 ・音声 ・動画など(種類による) | ・文書生成 ・画像生成 ・音声生成 ・動画生成など |
| LLM | ・テキストのみ | ・文書生成 ・翻訳 ・要約 ・質問応答など |
生成AIとは、テキスト・画像・音声・動画などのコンテンツ生成を目的としたAI技術の総称です。ChatGPTをはじめ、画像生成AI(Midjourney・DALL-Eなど)や音声生成AIなど、用途別にさまざまな種類が存在します。
一方、LLMは“生成AIの一種”です。ただし、「テキスト(言語)の処理・生成」のみに特化したモデルで、画像や音声、動画などは生成できません。
また、ChatGPTなどはLLMの技術を応用した生成AIです。つまり、「すべてのLLMは生成AIだが、すべての生成AIのモデルがLLMではない」といえるでしょう。
LLMにはどんな種類がある?

LLMのモデルは、大きく「独自開発型(クローズドソース)」と「オープンソース型」の2種類に分類されます。
<LLMのモデルの種類>
| 比較ポイント | 独自開発型(クローズドソース) | オープンソース型 |
| ソースコード | 非公開 | 公開 |
| 利用方法 | API経由 | 自由に利用・改良可能 |
| 代表的なモデル(シリーズ) | ・GPT(OpenAI) ・Gemini(Google) ・Claude(Anthropic) | ・LLaMA(Meta) |
独自開発型モデルは、企業が独自に学習させたLLMです。内部構造や学習データは非公開で、基本的にはAPI経由での利用となります。
OpenAIのGPT・GoogleのGemini・AnthropicのClaudeが代表的です。
一方、オープンソース型モデルはソースコードが公開されており、ライセンス条件に従えば自由に利用・改良できます。MetaのLLaMAはよく知られた存在です。
また国内では、日本語性能に特化した国産LLMの開発も進んでいます。
<代表的な国産LLM>
- tsuzumi 2(NTTデータ)
- CC Gov-LLM(カスタマークラウド)
- Llama-3.1-ELYZA-JP-70B(KDDI・ELYZAの共同開発)
- Sarashina2 mini(ソフトバンク)
- cotomi v3(NEC)
- Takane 32B(富士通)
- PLaMo 2.0 Prime(Preferred Networks)
2026年3月には、デジタル庁が行政向けの国産LLM(ガバメントAI)を公募し、上記7件を選定・公表しました。日本語の語彙や価値観に適合したAIの行政における実装推進と、国産AIの育成・強化に取り組んでいます。
出典:デジタル庁|ガバメントAIで試用する国内大規模言語モデル(LLM)の公募結果
LLMを活用できる5つの場面
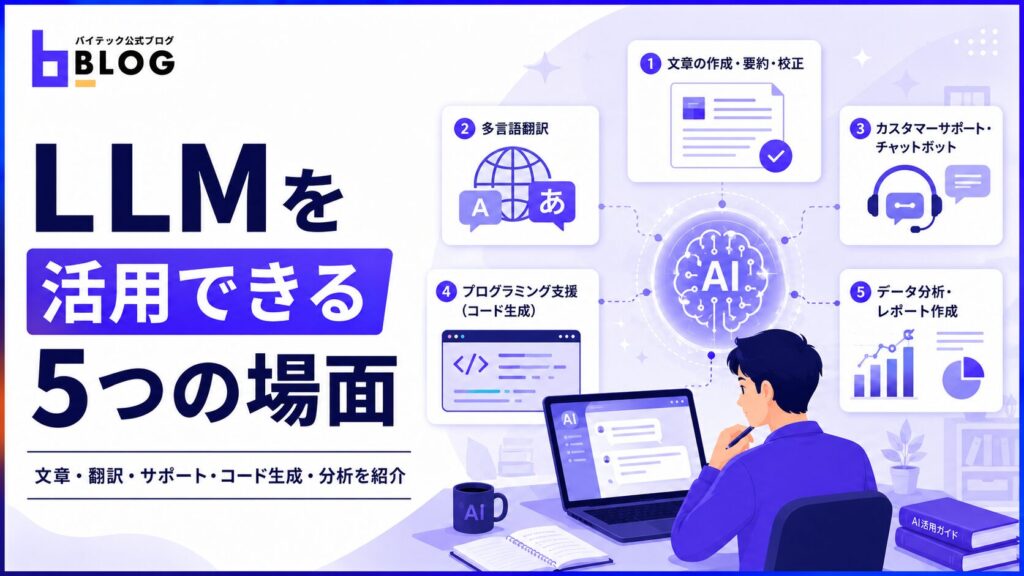
LLMは文章を理解・生成する能力を持つため、テキストを扱うあらゆる業務との親和性が高いAI技術です。翻訳・要約・コード生成などのタスクから、カスタマーサポートやデータ分析といった複合的な業務まで、幅広い場面で役立ちます。
ここでは、LLMを有効活用できる代表的な5つの場面を紹介しましょう。
文章の作成・要約・校正
LLMが最も得意とするのが、自然な言語を使ったあらゆる処理、つまり文章の作成や要約・校正です。
<LLMの文章処理能力が活用できる主な場面>
| 能力 | 業務活用例 |
| 文章の作成 | ・メールの下書き・報告書の作成や自動化 ・会議の発言内容のテキスト化・議事録作成 ・取材・商談内容の文字起こし |
| 文章の要約 | ・長文の記事・資料・レポートなどの要約 ・膨大なリサーチ情報の要約 |
| 文章の校正 | ・文書の文法やスペルのチェック、修正案提示 |
数千字におよぶ資料やレポートを数行にまとめたり、「箇条書きで」「200文字以内で」など細かい条件を指定して要約できます。
また、メールの下書きや報告書作成の自動化も可能なため、作業時間を大幅に削減できるでしょう。
さらに、文法の誤りや不自然な言い回しを検出して修正案を示す校正機能を使えば、取引先や顧客へ送る文書の品質を底上げできます。
他にも、会議の議事録作成や取材内容の文字起こしなど、日常業務に即活用できる有用な技術だといえるでしょう。
多言語翻訳
LLMは、多言語翻訳においても優れた能力を発揮します。
従来の機械翻訳では、文脈やニュアンスが失われて不自然な文章になることがありました。
一方、LLMは文章全体の流れや意図を踏まえて翻訳を行うため、より自然な表現で翻訳できます。
翻訳時は、「丁寧な表現で」「友人との会話のようにカジュアルなトーンで」といったスタイルの指定も可能です。専門用語や微妙なニュアンスも汲み取った翻訳により、ビジネス文書からSNS投稿まで幅広い用途に応じて使い分けできるでしょう。
さらに、LLMは複数の言語に対応しています。LLMの活用は、グローバルビジネスにおける多言語コミュニケーションの実現にも大いに役立つでしょう。
カスタマーサポート・チャットボット
企業のカスタマーサポートや社内ヘルプデスクには、LLMを活用したチャットボットの導入が進んでいます。
従来のFAQは、事前に用意されたルールに基づいて応答するため想定外の問い合わせには対応できませんでした。対して、LLMを組み込んだチャットボットはあいまいな質問にも柔軟に応答でき、より自然な対話が可能です。
よく寄せられる質問と回答をLLMに学習させておくと、より幅広い質問に的確に回答できるようになります。また、自動応答で24時間対応も可能になるため、顧客満足度の向上と同時にオペレーターの負担も大きく減るでしょう。
LLMのチャットボットへの活用は、カスタマーサポートに多くの面で貢献しています。
プログラミング支援(コード生成)
LLMの活用は、開発現場のプログラミング支援ツールにも広がっています。
「こんな機能を作りたい」と日本語で指示するだけで、PythonやJavaScriptなどのプログラミング言語でコードを自動生成できるのです。
さらに、バグの検出や修正案の提示・既存コードの最適化も可能なため、開発者の生産性は大幅に向上するでしょう。たとえば、以下のツールが挙げられます。
<LLMを活用した主なプログラミング支援ツール>
- GitHub Copilot(GitHub・OpenAIの共同開発)
- Amazon Q Developer(旧 Amazon CodeWhisperer / Amazon)
これまでプログラミングには高度な専門知識が必要でしたが、LLMの活用で誰でも簡易なプログラムを作成できるようになりました。
プログラミング支援におけるLLMの活用は、非エンジニアの業務効率化にも役立っています。
データ分析・レポート作成
複雑なデータの分析や結果をレポートにまとめる作業でも、LLMが大いに役立ちます。
たとえば、膨大な従業員データからハイパフォーマーの傾向を探したり、キャンペーン結果から最適な施策を導き出すことが可能です。
また大量のデータや情報をもとに、論理的でわかりやすいレポートや提案資料を作成できます。しかも、手作業では何時間もかかる分析と文書化を短時間で行えるため、作業時間を大幅に短縮できるのです。
分析からデータの加工、レポーティングに至る一連のプロセスをLLMがサポートするため、専門家でなくても業務を行えます。LLMの活用は、企業の日常業務に大きなメリットをもたらすでしょう。
【5ステップ】LLMが言語処理を行う流れ
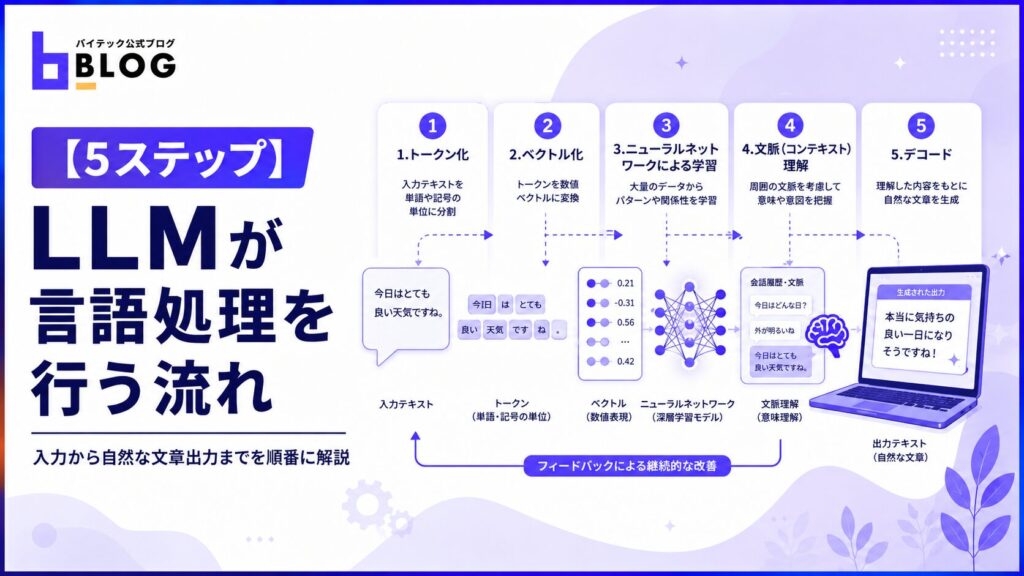
LLMは、入力されたテキスト(言語)をそのまま理解できるわけではありません。テキストをコンピュータが理解・処理できる数値データへ変換し、膨大な学習を経てはじめて自然なテキストで出力できるのです。
ここでは、LLMが言語を処理して出力に至るまでの5つのステップを順番に解説します。
1.トークン化|文章を最小単位に分割
LLMが言語を処理する最初のステップが「トークン化」です。
LLMはまず、入力されたテキストを「トークン」と呼ばれる最小単位に分割します。
トークンとは、単語・句読点・記号などテキストの最小要素です。英語では単語や句読点がトークンの最小単位となり、日本語では「AI」「を」「利用」「する」のように細かく分割されます。
コンピュータはテキストをそのままでは処理できません。よって、トークン化は次のステップでコンピュータが処理しやすい数値データにテキストを変換するための前処理です。
トークン化によってテキストの効率的な処理が可能となり、モデルの精度も向上するため、LLMの重要なステップだといえるでしょう。
2.ベクトル化|トークンを数値データに変換
トークン化の次に行われるのが「ベクトル化」です。トークン化によって分割されたデータを、コンピュータが処理できるように数値データ(ベクトル)へ変換します。
特筆すべきは、ベクトル化によって単語間の意味的な近さを「位置関係」として表現できるようになる点です。
たとえば、「猫」と「犬」など意味が近い単語は、ベクトル空間上で近い位置に置かれます。対して、「猫」と「ロケット」のように関連が低い単語は遠い位置に置かれるといった具合です。
上記のベクトル表現により、単語を1次元的な順序だけでなく、「意味のつながり」を踏まえた高次元な位置関係として把握できます。複雑な構造を持つ人間の言語を扱ううえで、不可欠なステップだといえるでしょう。
3.ニューラルネットワークによる学習
ベクトル化されたデータは、LLMの中核ともいえるニューラルネットワークを通して学習されます。
ニューラルネットワークとは、人間の脳の神経細胞(ニューロン)を模した多層構造の機械学習モデルです。多くのLLMでは「Transformer」というアーキテクチャが基盤に使われています。
Transformerのニューラルネットワークでは、数千億ものパラメータ(媒介変数)を持つ大規模な言語モデルを使用可能です。ゆえに、大量のデータを繰り返し処理しながら、単語の出現パターンだけでなく単語間の関係性や文脈まで理解・学習していきます。
ニューラルネットワークでの学習で蓄積された大量のデータが、LLMの高度な言語処理の基盤となるのです。
4.文脈(コンテキスト)理解
ニューラルネットワークで学習されたデータは、セルフアテンション(自己注意機構)と呼ばれる仕組みによって処理されます。
セルフアテンションとは、文章内の各要素が他の全要素を同時に参照し、関係性の重要度を評価することで文脈を理解する手法です。
たとえば、「彼は昨日の会議で重要な発言をした」という文では「彼」と「発言」の関係性が強いと判断されます。各関係性に付けられた重要度をもとに、次にくるトークンの確率が計算され、予測されるのです。
文脈を踏まえて次のトークンを的確に予測できるのは、セルフアテンションによる重要度評価があるからこそといえるでしょう。
5.デコード|自然な文章として出力
LLMによる言語処理の最終ステップが「デコード(テキスト変換)」です。
セルフアテンションによる文脈理解で得た情報をもとに、モデルは次にくるトークンを確率的に選び出します。デコードでは、予測と選出を繰り返して形成されたトークン列を、再び人間が読める自然なテキストに変換して出力するのです。
たとえば、「私はご飯を___」と入力すると「食べた」というトークンが選ばれて出力され、また次が予測・出力されます。生成と変換の繰り返しで、意味の通った文章がだんだん完成していくのです。
まるで人間が書いたように自然な文章を出力するデコードは、人間と自然に対話できるLLMに必須のステップといえるでしょう。
<LLMが言語を処理する【5つのステップ】>
| ステップ | 概要 |
| ①トークン化 | テキストを単語・記号などの最小単位(トークン)に分割する |
| ②ベクトル化 | トークンを意味の位置関係を保った数値データに変換し、コンピュータが理解・処理できる形にする |
| ③ニューラルネットワーク学習 | 多層構造のネットワークを通して大量のデータを処理しながら特徴を学習し、単語間の関係性・文脈・出現パターンを習得する |
| ④文脈理解 | セルフアテンションで文脈を把握し、次のトークンを予測する |
| ⑤デコード | トークン列を人間が読める自然なテキストに変換して出力する |
LLM活用における注意点5選

LLMはさまざまな業務を効率化できる一方、導入・運用にあたって把握しておくべきリスクも存在します。特性を正しく理解せずに活用すると、情報漏洩や法的問題につながりかねません。
ここでは、LLMを業務で活用するうえで注意すべき5つのポイントを解説します。
ハルシネーション
ハルシネーションとは、AIが事実とは異なる情報や存在しない情報を、さも正しいかのように出力してしまう現象です。「でたらめ」「虚偽の生成」を意味し、日本語では「幻覚」と訳されます。
ハルシネーションの発生は、学習データに含まれる誤情報や偏り、モデルの学習プロセスなど構造上の問題が原因です。特に、医療・法律・金融といった正確性が求められる分野においては、深刻なリスクとなります。システムの技術の進化とともに軽減が予想されるものの、言語モデルの性質上、完全な防止は難しいでしょう。
よって、ハルシネーションが発生する前提でLLMを利用し、出力内容は必ず人間が確認するといった運用体制の構築が不可欠です。
機密情報・個人情報の漏洩リスク
クラウド経由でLLMを利用すると、プロンプトとして入力した内容が外部サーバーへ送信される場合があります。業務上の機密データや顧客の個人情報をそのまま入力してしまうと、情報漏洩などの高いリスクにつながりかねません。
<LLMの情報漏洩リスクへの主な対策>
| 利用環境 | 対策 | 内容 |
| 非クラウド | オンプレミス導入 | 自社内にLLMシステムを設置し、入力データが外部サーバーへ送信されない環境で運用する |
| クラウド経由 | オプトアウト設定 | 入力データがAIモデルの学習に利用されないよう設定する |
| すべて | 利用ガイドライン策定・従業員教育の実施 | LLM利用にあたって社内の情報管理体制を強化する |
対策として有効なのは、機密性の高い業務に関してはオンプレミス(自社内)でLLMを導入することです。もしくは、ChatGPTのように、入力データをAIモデルの学習に使用させない「オプトアウト」機能の設定をする方法もあります。
加えて、社内でLLMを利用する場合は、利用ガイドラインの策定や従業員への教育など情報管理体制の整備も必要です。
クラウドでもオンプレミスでも、環境に応じた情報漏洩防止策を実施しましょう。
著作権侵害のリスク
LLMが学習材料として使用する大量のテキストデータの中には、著作権で保護されたコンテンツが含まれる場合があります。つまり、LLMが生成したテキストをそのまま公開・利用してしまうと著作権侵害に問われるリスクがあるのです。
現時点では、学習データの著作権に関する法的整備については世界各国で議論が続いています。まだ明確なルールが固まっていない部分も多いため、慎重な対応が必要です。
今後の法的整備の動向に注目しながら、社内でチェック体制を整える姿勢が求められます。
LLMを活用する際は、出力された内容をそのまま流用せず、必ず人間の目で確認・修正してから使用するという認識を持ちましょう。
プロンプトインジェクション攻撃
プロンプトインジェクションとは、サイバー攻撃の手法の一つです。悪意ある利用者が巧妙な指示(プロンプト)をLLMに入力し、本来は禁じられた動作の実行や不適切な情報の出力をさせたりします。
意図せず企業の機密情報や個人情報が出力されたり、根拠のない誤情報が拡散されるリスクがあるため注意が必要です。
<プロンプトインジェクションへの主な対策>
| 対策 | 内容 |
| 入力制限 | ユーザーが入力できるプロンプトの内容・形式を制限する |
| 出力フィルタリング | 不適切な内容が含まれる出力を検知・除外する仕組みを設ける |
| 教育・周知 | 従業員にリスクや安全な利用方法の周知を継続的に行う |
対策としては、プロンプトの入力制限、出力結果のフィルタリング、従業員へのリスク周知と継続的な啓蒙教育が有効です。
技術面と教育面の両方から、LLMを利用するうえでの課題に取り組みましょう。
最新情報への対応限界
LLMは、事前に学習されたデータをもとに回答を生成するAIモデルです。よって、学習データの収集時点以降に起きた出来事や、最新情報についての正確な回答は難しい場合があります。
基本的に、LLMは直近のニュースやスポーツの試合結果・リアルタイムの株価などへの対応は得意ではありません。最新情報を踏まえた生成結果が得られないという特徴は、LLMの限界を示す指標の一つといえるでしょう。
なお、上述のLLMの能力の限界を補う技術にRAG(Retrieval-Augmented Generation:検索拡張生成)があります。外部のデータベースから最新情報を検索してLLMの回答に組み合わせる仕組みのため、より正確で最新の回答が可能です。
信頼性の高い出力のためにも、LLMとRAGの組み合わせは有効だといえるでしょう。
【FAQ】LLMに関するよくある質問

LLMについて、初めて知る方からビジネス担当者まで多くの方が疑問に思うポイントをQ&A形式でまとめました。
「そもそもLLMとは何か」という基本的な問いから、ChatGPTや生成AIとの違い、日本語対応モデルの現状までカバーしています。LLMへの理解と、業務活用の判断にお役立てください。
LLMとはわかりやすくいうと何ですか?
LLMとは、膨大なテキストデータを学習し、人間のように自然な文章を理解・生成できるAI技術です。「Large Language Model(大規模言語モデル)」の略称で、ChatGPTやGeminiなどの生成AIサービスの基盤技術として使われています。
スマートフォンの予測変換と同じ原理で「次に続く単語」を予測しますが、LLMの規模は桁違いに大きく、より複雑な文脈まで理解します。「知りたいことを尋ねると、人間のような言葉で答えてくれるAIの中核技術」と理解するとわかりやすいでしょう。
専門的なプログラミング知識がなくても日常業務やビジネスに活用できる、実用性の高いAI技術です。
ChatGPTとLLMの違いは何ですか?
LLMがAI技術そのもの(基盤モデル)を指す一方、ChatGPTはLLMの技術を応用して作られた対話型生成AIサービスの一つの名称です。両者の関係は、「エンジン(LLM)」と「エンジンを搭載して動く車(ChatGPT)」にたとえるとわかりやすいでしょう。
<LLMとChatGPTの関係>
| 用語 | 位置づけ | 主な例・類似例 |
| LLM | 生成AIを動かす基盤技術 | ・GPTシリーズ ・Geminiシリーズ ・Claudeシリーズ |
| ChatGPT(OpenAI) | LLMの技術を応用して動く生成AIサービス・モデル | ・Gemini(Google) ・Claude(Anthropic) |
ChatGPTは、OpenAIが開発したGPTシリーズというLLMを搭載した、チャット形式の対話に特化した生成AIです。同様に、GoogleのGeminiはGeminiというLLMを、AnthropicのClaudeはClaudeというLLMをそれぞれ搭載しています。
すなわち、ChatGPTはLLMの応用例の一つであり、LLMとChatGPTはイコールではありません。
LLMと生成AIは同じものですか?
LLMと生成AIは異なります。
生成AIは、テキスト・画像・音声・動画などのコンテンツを自律的に生成できるAI技術の総称です。
一方LLMは、生成AIのなかでも「テキストの処理・生成」に特化した言語モデルを指します。
<生成AI・LLM・LMMの包含関係>
| 用語 | 位置づけ | 扱えるデータ |
| 生成AI | AI技術の総称 | テキスト・画像・音声・動画など |
| LLM | 生成AIの一種 | テキストのみ |
| LMM(大規模マルチモーダルモデル) | LLMの発展形 | テキスト・画像・音声・動画など複数形式 |
たとえば、画像生成が可能なMidjourneyやDALL-Eは生成AIですが、LLMではありません。LLMが扱えるのは、あくまでもテキストの処理だけです。
ただし近年は、テキスト以外に画像や動画など複数の形式を扱えるLMM(Large Multimodal Model)も登場しています。GPTやGemini・ClaudeもLMMの一種です。
大規模マルチモーダルモデルと呼ばれ、LLMが進化したモデルだといってよいでしょう。
LLMとRAGの違いは何ですか?
LLMは、事前に学習したデータをもとに文章を生成するAIモデルです。
一方、RAG(Retrieval-Augmented Generation:検索拡張生成)はLLMの能力の限界を補完する技術を指します。外部のデータベースからLLMが不得意なリアルタイムの情報を収集し、LLMがより正確で最新の回答を生成できるようにする仕組みです。
LLMが「学習済みの知識だけで答える」のに対し、RAGは「外部の情報を参照しながら答える」といえるでしょう。
社内規定・最新ニュース・製品情報などLLMの学習データに含まれない情報を扱いたい場面では、RAGとLLMの併用が有効です。
日本語に強いLLMはありますか?
近年、日本語処理に強い国産LLMの開発が進行中です。
2026年3月のデジタル庁の資料によると、政府の行政業務(ガバメントAI)向けに試用する国産LLMとして以下の7件が選定されています。
<代表的な国産LLM>
- tsuzumi 2(NTTデータ)
- CC Gov-LLM(カスタマークラウド)
- Llama-3.1-ELYZA-JP-70B(KDDI・ELYZAの共同開発)
- Sarashina2 mini(ソフトバンク)
- cotomi v3(NEC)
- Takane 32B(富士通)
- PLaMo 2.0 Prime(Preferred Networks)
上記は日本語の語彙や表現、日本の文化や価値観への適合性が評価され、行政への活用に向けた試用が進められているところです。
また、海外モデルでもGPT-4o以降のモデルやGemini・Claudeは、日本語への対応が大幅に強化されています。
出典:デジタル庁|ガバメントAIで試用する国内大規模言語モデル(LLM)の公募結果
LLMはどこで使えますか?
LLMは直接使うというよりも、LLMを搭載したAIサービスを通じて利用するのが一般的です。
代表的なサービスにはChatGPT・Gemini・Claudeなどがあり、テキストボックスに質問や指示を入力するだけで利用できます。自然な日本語で話しかけるだけで文章生成・翻訳・要約などの機能を利用でき、特別なプログラミング知識も不要です。
また企業では、LLMをAPI経由で自社サービスに組み込んで活用する方法も広く行われています。
LLMは、個人利用から企業での本格導入まで、目的や規模に応じてさまざまな形で使えるといえるでしょう。
まとめ
LLMは、膨大なテキストデータの学習によって、人間が話すように自然な言語の処理・生成を可能にするAI技術です。文章作成やカスタマーサポート・コード生成・データ分析など、テキストを扱うあらゆる業務での活用が進んでいます。
一方で、ハルシネーションや情報漏洩・著作権侵害といったリスクも存在するため、出力内容の確認や社内ガイドラインの整備が不可欠です。業務効率化と安全な運用を両立するために、LLMの特性と限界を理解したうえでの利用が求められます。
近年は、マルチモーダルモデルへの進化やAIエージェントの開発も加速しており、今後はより人間に近い知的支援も期待できるでしょう。
まずは身近なサービスから試して、求める機能との適合性を確かめてみてください。


