【なぜ重要?】ファインチューニングとは|仕組みや実施手順・注意点について

AIの活用が競争力に直結する時代において、汎用モデルをそのまま業務導入するだけでは、専門性や精度の面で限界が生じるケースが増えています。ファインチューニングは、事前学習済みモデルに特化したデータを追加学習させる手法です。
追加学習によってモデルのパラメータを微調整することで、特定の業務や分野に最適化された専門AIを実現できます。ファインチューニングはゼロからの開発と比べて、コストと時間を大幅に抑えながら、高精度な専門AIを構築できます。
本記事では、ファインチューニングの仕組みから実施手順・注意点などを解説します。
ファインチューニングとは

ファインチューニング(Fine-tuning)とは、事前学習済みのAIモデルに対して特定のタスクや領域に特化したデータで追加学習を行い、パラメータを微調整する手法です。
日本語では、「微調整」とも訳されます。ここでは、ファインチューニングと混同されやすい関連手法との違いを3項目で解説します。
事前学習(プレトレーニング)との違い
ファインチューニングは、事前学習が構築した汎用知識を土台にして、特定のタスクや業務に特化させる工程です。事前学習は、インターネット上の膨大なテキストや画像データを使い、モデルの基礎的な理解力と汎用的な知識を構築する工程です。
ファインチューニングは、事前学習済みモデルを基にして、特定の目的に合わせてパラメータを最適化する追加学習にあたります。
| 比較項目 | 事前学習 | ファインチューニング |
| 目的 | 汎用的な知識の獲得 | 特定タスクへの特化 |
| データ量 | 大規模(数百GB〜TB級) | 小規模(数百〜数千件) |
| 計算コスト | 非常に高い | 比較的低い |
| 学習時間 | 数週間〜数ヶ月 | 数時間〜数日 |
例えるなら、事前学習が「基礎体力づくり」で、ファインチューニングが「専門スキルを磨く特訓」というイメージです。事前学習済みモデルの初期パラメータを活用することで、モデルは新しいタスクへ迅速に適応できます。
ゼロからのトレーニングに比べて、ファインチューニングのほうが効率的に高精度なカスタマイズを実現できます。
RAG・プロンプトエンジニアリングとの違い
ファインチューニング・RAG・プロンプトエンジニアリングは、いずれもAI出力を改善する手法ですが、モデルへの干渉度が根本的に異なります。
<3手法の概要>
- ファインチューニング:モデル内部のパラメータを更新して、知識や振る舞いを恒久的に変更する
- RAG:モデル自体を変更せず、外部データベースから関連情報を検索してプロンプトに組み込み、回答を生成する
- プロンプトエンジニアリング:モデルへの入力指示を工夫することで、出力の質やスタイルを一時的に調整する
<3手法の特性比較>
| 手法 | モデルの変更 | 最新情報への対応 | コスト目安 | 主な用途 |
| ファインチューニング | あり(恒久的) | 困難 | 高い | 専門知識・応答スタイルの固定 |
| RAG | なし | 容易 | 中程度 | リアルタイム情報の参照 |
| プロンプトエンジニアリング | なし | 対応可 | 低い | 出力スタイルの調整 |
プロンプトエンジニアリングのコスト面での負担は3手法の中で最も少ない一方、モデルが持たない専門知識の補完には対応しきれない面があります。実務での選択基準としては、まずプロンプトエンジニアリングで対応できるかを検証するのが一般的な流れです。
外部の最新情報を参照したい場合はRAGを、モデル自体の知識や応答スタイルを根本的に変更したい場合にはファインチューニングを検討します。
転移学習との関係性
ファインチューニングは転移学習の一手法として位置づけられており、追加データの量に応じて他の転移学習手法と使い分けられます。転移学習とは、あるタスクで学習済みのモデルの知識を別のタスクへ再利用する手法の総称です。
転移学習には大きく2種類あり、重みを固定して特徴量抽出器として使う方法と、重みを再学習させる方法が存在します。後者がファインチューニングにあたり、モデルの重みの一部または全体を更新してタスクへの適応を図ります。
| 手法 | 重みの扱い | 必要データ量 | 学習の深さ |
| 重みを固定する転移学習 | フリーズ(変更なし) | 少量でも可 | 浅い(出力層のみ) |
| ファインチューニング | 一部または全体を更新 | 比較的多量 | 深い(複数層を更新) |
使い分けの基準としては、追加データが十分に用意できる場合はファインチューニングが適しているでしょう。データが少ない状況では、重みを固定する転移学習の手法が有効とされています。
ファインチューニングは、既存モデルの広範な知識を活かしながら、新しいタスクへの特化した調整を加える手法です。ゼロから学習する場合に比べて、過学習リスクを抑えながら高精度なモデルを効率的に構築できます。
ファインチューニングが重要とされる3つの理由

ファインチューニングが多くの企業や開発現場で広く採用される背景には、明確な理由があります。ゼロからのモデル構築と比較したコスト面での優位性や、特定分野への高い適応力、少量データでの精度実現などが強みです。
ここでは、ファインチューニングが重要とされる3つの理由を順に解説します。
ゼロからの学習に比べてコストと時間を大幅に削減できる
大規模言語モデルや画像認識モデルをゼロから構築するには、膨大な計算リソースと長期間の学習時間が必要です。数百万〜数十億規模のパラメータを処理するためのインフラ整備だけでも、相当なコスト負担が生じます。
ファインチューニングでは、事前学習済みモデルを出発点とするため、追加データの準備にかかる負担を大幅に抑えられます。
OpenAIのGPTモデルでは、50〜100件程度のサンプルからでも効果的なファインチューニングが可能です。PEFTなどの効率的な手法と組み合わせると、大規模なインフラ投資なしでも高品質なモデルカスタマイズを実現できます。
費用対効果の高さが、企業規模を問わずファインチューニングが広く採用される理由の一つです。
<コスト削減につながる主な要因>
- 事前学習済みモデルを活用するため、学習データの収集・整備量を少量に抑えられる
- GPUなどの高性能ハードウェアの稼働時間を大幅に短縮できる
- PEFTなどの効率的手法により、大規模インフラなしでのカスタマイズが可能
専門分野や自社業務に特化したAIを構築できる
汎用的な事前学習済みモデルは幅広い知識を持ちますが、医療・法律・金融などの専門分野や企業固有の業務ルールには、対応しきれない場合があります。
ファインチューニングを実施することで、専門的な知識や業界特有の文脈をモデルに学習させられます。医療分野では、専門用語や診断データを用いたファインチューニングにより、専門的な質問への回答精度が向上するでしょう。
また、自社の製品マニュアルや顧客対応履歴を学習させると、ブランド独自のトーンで応答する社内特化型AIの構築も実現できます。
| 活用分野 | 学習データの例 | 期待できる効果 |
| 医療 | 診断データ・医療論文 | 専門用語への対応精度向上 |
| 法律 | 判例・契約書 | 法的文書の正確な解釈 |
| 社内業務 | マニュアル・対応履歴 | 自社ルールに沿った回答生成 |
少量のデータでも高い精度を実現しやすい
ファインチューニングでは、事前学習済みモデルの言語理解力や画像認識力を土台にするため、少量データでも高精度なモデルを構築しやすいのが特徴です。
事前学習済みのパラメータ初期値を保持しているため、新しいタスクへの収束が速くなります。パラメータの初期値が過学習を抑制し、汎化性能の維持にも役立ちます。
英語など大規模データで事前学習されたモデルは、低リソース言語のファインチューニングにも応用可能です。
少量データでも高品質な出力が得られる事例も、実際に報告されています。開発初期段階のプロトタイプ構築が迅速化されるため、初期投資を抑えながら短期間でPoC(概念実証)を実施できます。
<少量データでのファインチューニングが有効なケース例>
- 特定業界の専門用語辞典や社内FAQを数百件程度で学習させる場合
- 低リソース言語の翻訳モデルを英語ベースのモデルから転用する場合
- 新製品リリース後に収集した顧客フィードバックを即座に追加学習させる場合
ファインチューニングの仕組み
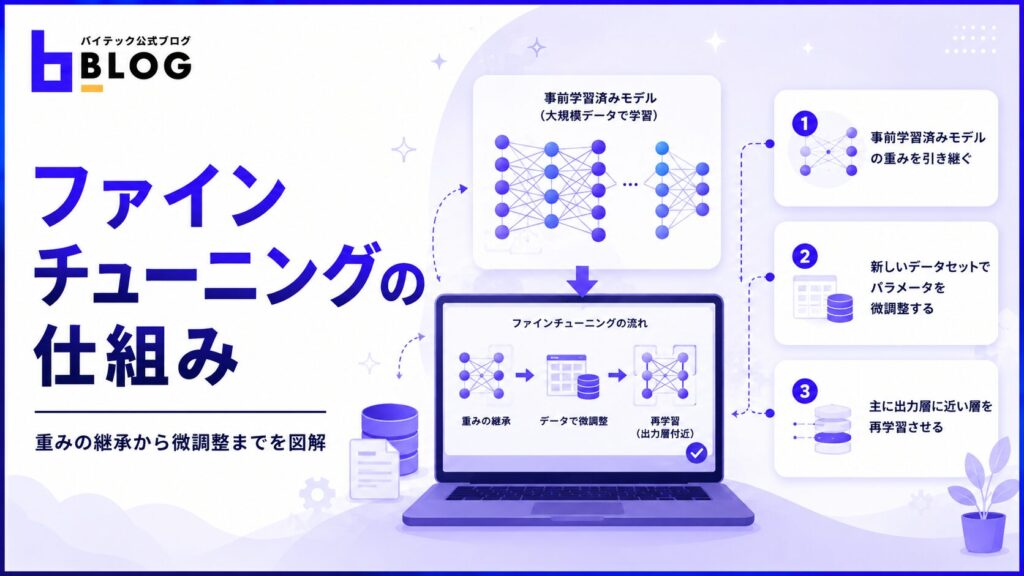
ファインチューニングは、事前学習済みモデルを起点とした一連の工程で成り立っています。内部でどのような処理が行われているかの理解は、適切な手法の選択や精度改善の判断に直結するでしょう。
ここでは、ファインチューニングの重みの引き継ぎ・パラメータの微調整・再学習させる層の選択という3つの観点から解説します。
事前学習済みモデルの重みを引き継ぐ
ファインチューニングの出発点は、事前学習済みモデルの重みをそのまま引き継ぐことにあります。事前学習済みモデルは、数百万〜数十億のパラメータを保有しています。パラメータとは、ニューラルネットワークの各ノードにおける重みやバイアスのことです。
事前学習済みモデルのパラメータは、大規模な学習過程で既に最適化が施されています。
画像認識モデルであれば、初期層でエッジやテクスチャなどの基本的な視覚特徴を捉える能力を獲得済みです。
深い層では、より抽象的な概念を識別する力も備わっています。言語モデルの場合、文法構造や単語間の関係性といった汎用的な言語理解力を、事前学習を通じて習得済みです。
既存の知識基盤を活用することで、ゼロからモデルを構築する場合に比べて学習を大幅に効率化できます。
<モデル別の事前習得知識の例>
| モデルの種類 | 習得している知識の特徴 |
| 画像認識モデル | エッジ・テクスチャなどの視覚特徴、抽象的概念の識別能力 |
| 言語モデル | 文法構造・単語間の関係性・文脈理解力 |
新しいデータセットでパラメータを微調整する
事前学習済みの重みを引き継いだモデルに対して、特定タスクに対応した新しいデータセットを使いパラメータを微調整します。微調整のプロセスでは、フォワードパスとバックプロパゲーションを繰り返して損失関数の値を下げていきます。
<主要プロセスの概要>
- フォワードパス:モデルが入力データを処理して予測値を出力する工程
- バックプロパゲーション:予測誤差をもとにパラメータの重みを更新する工程
ファインチューニングでは、事前学習時よりも意図的に小さい学習率を採用します。学習率を低く抑えることで、モデルが事前学習で獲得した広範な知識を損なわずに新しいタスクへ適応できます。
LLMのファインチューニングでは、質問と理想的な回答のペアをデータセットとして準備するのが一般的です。モデルが質問と回答のパターンを学習することで、特定タスクへの対応力が着実に高まります。
バッチサイズやエポック数などのハイパーパラメータの設定は、複数回の試行を経て最適化するのが一般的です。
<ファインチューニングにおける主なハイパーパラメータ>
| ハイパラメーター | 役割 |
| 学習率(Learning Rate) | パラメータの更新幅を制御する |
| バッチサイズ | 一度に処理するデータ件数を指定する |
| エポック数 | 学習データを何周処理するかを指定する |
主に出力層に近い層を再学習させる
ニューラルネットワークの入力に近い層は、エッジや文法構造といった汎用的な特徴を捉えます。出力に近い層ほど、タスク固有の具体的な特徴を捉える傾向があります。
ファインチューニングでは一般に、入力層に近い重みをフリーズして出力層に近い層のみを再学習させるのが基本的なアプローチです。新しいタスクが元のタスクに類似しているほど、フリーズできる層の割合が多くなります。
再学習が必要な範囲が小さくなる分、計算コストの削減にも直結します。既存モデルの最終層に新たな層を追加したうえで、追加層のみをトレーニングするのも実用的です。
学習対象を出力層付近の限定した層に絞ることで、計算コストを抑えた効率的な追加学習が可能になります。事前学習で培った汎用的な基礎知識を維持しながら、新しいタスクへの対応力を同時に獲得できるのです。
<再学習対象の層の選び方>
| 状況 | 再学習させる範囲 |
| 新タスクが元タスクに類似している場合 | 出力層付近の少数層のみ |
| 新タスクが元タスクと大きく異なる場合 | 出力〜中間層など広い範囲 |
| 用意できるデータ量が少ない場合 | 再学習範囲を絞って過学習を抑制 |
ファインチューニングの主な種類3つ
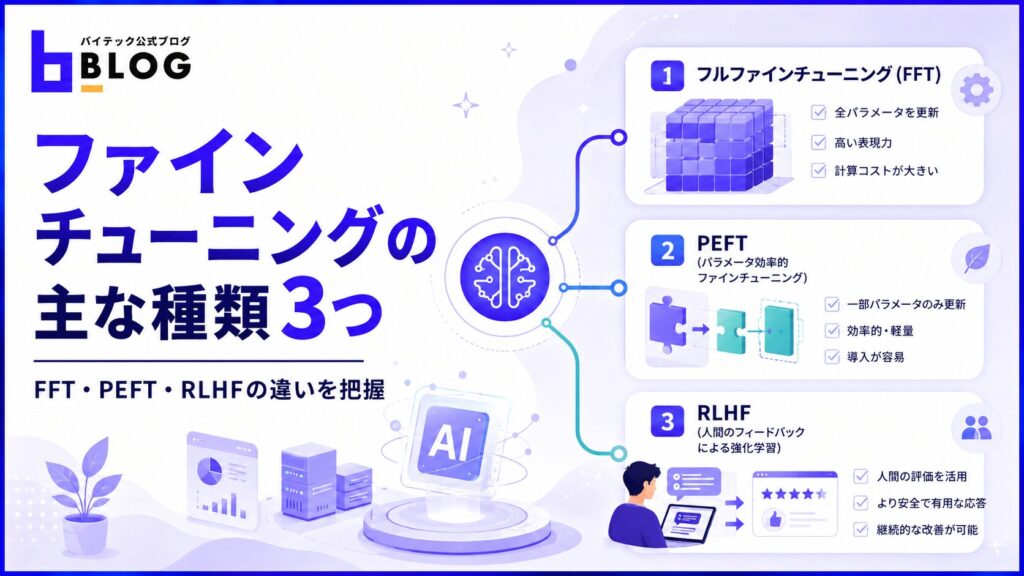
ファインチューニングには、目的や計算リソースの制約に応じて選べる複数の手法が存在します。手法ごとに更新するパラメータ範囲・計算コスト・適用場面が、大きく異なるのが特徴です。
ここでは、フルファインチューニング・PEFT・RLHFの3種類の特性と使い分けの基準を解説します。
フルファインチューニング(FFT)
フルファインチューニング(FFT)は、ニューラルネットワークのすべてのパラメータを更新する手法です。概念的には事前学習と類似した工程であり、使用するデータセットとパラメータの初期状態が異なります。
すべての層を学習対象とするため、モデルへの影響は3手法の中で最大です。精度面では、一般的に3手法の中で最良の結果が得られるとされています。計算資源が豊富で、高品質データを大量に用意できる環境に最も適した手法です。
<フルファインチューニング(FFT)の基本情報>
| 項目 | 内容 |
| 更新対象 | モデルのすべてのパラメータ |
| 必要な計算リソース | 非常に大きい(高スペックGPUが必須) |
| 精度水準 | 3手法の中で最高水準 |
| 主なリスク | 大量の計算コスト・低品質データによるモデル全体への悪影響 |
数億〜数十億個のパラメータを持つ大規模モデルでは、全パラメータ更新に膨大な計算リソースとメモリが必要になります。
学習データの質が不十分な場合、事前学習で獲得した知識ごとモデル全体に悪影響が及ぶリスクもあります。計算資源が潤沢で、データ量も十分に確保できる環境に向いた手法です。
PEFT(パラメータ効率的ファインチューニング)
PEFT(Parameter-Efficient Fine-Tuning)は、モデルの一部パラメータのみを学習対象とする、計算効率型のファインチューニング手法の総称です。フルファインチューニングと比べ、メモリと計算コストの両面で負担が大幅に軽減されます。
PEFTは、わずか数パーセントのパラメータを学習させるだけで、フルファインチューニングに匹敵する精度を実現できるのが特徴です。破滅的忘却の軽減にも効果的とされており、事前学習で獲得した知識を保持しやすいのも強みになります。
<PEFTの代表的な手法>
| 手法 | 概要 |
| LoRA | 重み行列にアダプター行列を並列追加し、アダプター部分のみを学習させる |
| QLoRA | LoRAにモデルの量子化を組み合わせ、さらにメモリ効率を高めた手法 |
| Prefix Tuning | トランスフォーマの各層にタスク固有のベクトルを追加する |
| Prompt Tuning | 学習可能なソフトプロンプトを導入して出力を調整する |
LoRAとQLoRAは特に、GPUメモリが限られた環境で有効に機能する傾向があります。コストや計算資源に制約がある実務環境では、PEFTが最初に検討すべき現実的な選択肢です。
RLHF(人間のフィードバックによる強化学習)
RLHF(Reinforcement Learning from Human Feedback)は、人間のフィードバックをもとにモデルを強化学習で調整する手法です。教師ありファインチューニング(SFT)では、ラベル付きの具体例を通じてモデルに振る舞いを学ばせる仕組みです。
一方、「役に立つ」「事実の正確さ」「共感」といった抽象的な品質をデータだけで教えるのは、SFTには限界があります。
<RLHFのプロセス>
- モデルに複数の回答を生成させる
- 人間のテスターが回答の品質を評価する
- 評価データをもとに報酬モデルをトレーニングする
- 報酬モデルを活用した強化学習でLLM自体を改善する
ChatGPTの開発においてRLHFが重要な役割を果たしたことは、広く知られた事例です。ハルシネーションの抑制や、倫理的に不適切な出力の防止にも効果が確認されています。
人間の感覚や価値観を反映した高品質なモデルを構築したい場面で、RLHFは特に有効な手法です。
【場面別】ファインチューニングの活用事例4選

ファインチューニングは、テキスト処理から画像認識まで、幅広い領域で実用化が進んでいます。どのような場面で活用されているかを把握することで、自社への導入イメージが湧きやすくなるでしょう。ここでは、ファインチューニングの代表的な4つの活用事例を解説します。
カスタマーサポート向けチャットボットの構築
カスタマーサポート向けチャットボットは、ファインチューニングの効果が実務レベルで最も明確に現れる用途の一つです。汎用LLMは一般的な会話能力を備えていますが、特定企業の製品情報やサービスルール、業界固有の言い回しへの対応には限界があります。
顧客対応の履歴データや自社のFAQ、サービス規約などを学習データとして活用することで、「返金対応」「商品トラブル」といった具体的なシナリオにも的確に応答できるAIを構築できます。
<ファインチューニングで強化できる対応シナリオの例>
- 商品の返金・返品対応に関する問い合わせへの回答
- 利用規約や会員制度に関する詳細な案内
- トラブル発生時の初期対応フローの案内
指示チューニング(インストラクションチューニング)を組み合わせることで、ユーザーの質問意図を正確に解釈し、適切な形式で回答する精度を高められます。
対応品質の均一化と応答速度の向上を同時に実現できるのが、ファインチューニング適用の大きな強みです。結果として、顧客満足度の継続的な改善にもつながります。
医療・法律・金融など専門分野への適用
医療・法律・金融など高い専門性が求められる分野では、汎用LLMの回答精度が専門家水準に達しないケースが多く見られます。ファインチューニングを実施することで、専門的な知識や業界固有の文脈をモデルに内在化させ、実用水準の回答生成が可能になります。
<専門分野別のファインチューニング活用イメージ>
| 分野 | 学習データの例 | 主な活用用途 |
| 医療 | 病歴データ・医薬品情報・診断事例 | 専門用語への正確な対応・診断支援 |
| 法律 | 判例・法令データ | 契約書審査・法的リスクの把握 |
| 金融 | 取引データ・市場動向情報 | リスク管理・投資判断の支援 |
医療分野では、病歴データや医薬品情報を学習させることで、専門用語を正確に扱えるモデルを構築できます。法律・金融分野でも、判例や取引データを学習させることで、専門的な判断支援に特化したAIの実装が現実的な選択肢となってきました。
特に金融分野では、リスク管理や投資判断の領域での実用化に向けた開発も進んでいます。国内外で業界特化型LLMへの関心が高まっており、ファインチューニングは中核技術として広く認識されています。
社内文書・マニュアルを学習させた業務特化AI
企業が保有する社内文書やマニュアル、業務ルールなどは非公開情報であるため、汎用モデルでは対応できない領域です。社内データを用いたファインチューニングを実施することで、自社固有の知識を反映した業務特化型AIを構築できます。
社内の問い合わせ対応システムに組み込む場合、社内規定や手続き方法に関する質問への的確な回答を自動生成できるようになります。
<社内データを活用したファインチューニングの主な用途>
- 社内規定・手続きに関する問い合わせへの自動回答
- 社内独自の専門用語や略語の正確な理解と応答
- ブランド固有のトーンやコミュニケーションスタイルの再現
社内独自の専門用語や略語をモデルに習得させることで、RAGだけでは対処しにくい場面にも対応できます。ブランド固有のコミュニケーションスタイルを学習させることで、対外的な文書作成やマーケティング用途への応用も広がるでしょう。
ただし、機密性の高い情報を学習データに含める場合は、セキュリティ面での確認を十分に行う必要があります。
画像認識・物体検出モデルの精度向上
ファインチューニングは、LLMだけでなく画像認識・物体検出など、コンピュータビジョン分野でも幅広く活用されています。
大規模画像データセットで事前学習されたモデルをベースに、特定タスク向けのデータでファインチューニングを実施することで、高精度な画像分類モデルを効率的に構築できます。
たとえば、ImageNetで事前学習されたResNetやEfficientNetをベースとして活用することで、工場での不良品検出や鳥の種別分類といった特化型モデルの開発が可能です。
<コンピュータビジョン分野での主な活用事例>
- 製造業:工場ラインでの不良品・欠陥品の自動検出
- 農業・自然科学:植物の病害検出や動植物の種別分類
- 画像生成:Stable DiffusionへのLoRA適用による特定スタイルのカスタマイズ
物体検出の領域では、Detectron2やMMDetectionなどのツールキットが公開されており、事前学習済みモデルとソースコードがセットで提供されています。
比較的少ない手順でファインチューニングを実施できる環境が整っており、実務での導入障壁の低さが活用拡大を後押しする要因の一つです。画像生成の領域では、Stable DiffusionにLoRAを適用することで、特定の描写スタイルへのカスタマイズが実現できます。
【5ステップ】ファインチューニングの実施手順

ファインチューニングを適切に実施するには、一連の工程を正しい順序で踏む必要があります。工程ごとの役割を理解するのが、モデルの精度向上の前提条件です。ここでは、ファインチューニングの目的設定からデプロイ・継続改善までの5ステップを解説します。
1. 目的の明確化とベースモデルの選定
ファインチューニングの最初の工程は、解決すべき課題と達成目標を明確に定義することです。目的が曖昧なままでは、後工程での手法選択に迷いが生じ、コストと時間の損失につながります。
目的を定めたうえで、タスクの種類に応じた事前学習済みモデルの選定に進みます。モデル選定の際は、精度だけでなく、利用可能な計算リソースとのバランスも重要な判断軸の一つです。
<タスク別の代表的なベースモデル>
| タスクの種類 | 代表的なモデル |
| 自然言語処理(テキスト分類・対話) | BERT・GPTシリーズ |
| 画像認識・物体検出 | ResNet・EfficientNet |
高性能なモデルほど精度は出やすい傾向がありますが、計算リソースの消費量も増大する点には注意が必要です。
Hugging Faceなどのモデル共有サービスを活用することで、目的に合った事前学習済みモデルを効率よく見つけられます。性能とコストのトレードオフを踏まえた選定が、後工程の成否を左右するでしょう。
2. 学習データの準備と前処理
学習データの準備は、ファインチューニングの工程の中で最もドメイン知識と工数を要する段階です。データの品質と量がモデルの最終精度を直接左右するため、丁寧な前処理が欠かせません。
LLMのファインチューニングでは、質問と理想的な回答のペアをJSONL形式で用意するのが一般的な形式です。OpenAIのガイドラインでは、最低10件、通常50〜100件のサンプルが推奨されています。
<学習データ準備の主な作業内容>
| 作業 | 内容 |
| データ収集 | 目的に合った質問と回答のペア、社内文書などを収集する |
| データクレンジング | 欠損値・ノイズ・重複の除去、フォーマットの統一 |
| データ分割 | トレーニング・検証・テストセットへの振り分け |
収集したデータには欠損値やノイズが含まれるケースが多く、データクレンジングが必要になります。不要な情報の除去やフォーマットの統一が、前処理の中心的な作業です。準備したデータは、トレーニングセット・検証セット・テストセットの3つに分割します。
近年は、ローカルLLMを活用した学習データの自動生成・加工も普及しており、準備フェーズの効率化が進んでいます。
3. ファインチューニング手法とハイパーパラメータの設定
学習データの準備が整ったら、ファインチューニングの手法とハイパーパラメータの設定段階に移ります。手法の選択は、データセットのサイズ・計算リソースの制約・求める精度のバランスを踏まえた判断が必要です。
<手法の選択基準>
- フルファインチューニング(FFT):タスク固有のデータが大量にあり、計算資源が潤沢な場合に適している
- PEFT(LoRA・QLoRAなど):コストや時間に制約がある場合に有効で、フルファインチューニングに匹敵する精度を実現できるケースもある
設定するハイパーパラメータの中で、特に学習率の調整は慎重さが求められます。学習率が大きすぎると、事前学習で獲得した知識が失われるリスクがあります。逆に小さすぎると、学習が十分に進まず精度向上が見込めません。
過学習を防ぐために、適切なエポック数の設定は重要な調整項目の一つです。バッチサイズについても、データ量やモデルの規模に合わせた設定が必要です。事前学習済みモデルのどの層をフリーズして、どの層を更新するかの方針も、選定の段階で決定します。
4. トレーニングの実行とモニタリング
ハイパラメーターの設定が完了したら、GPUやTPUなどの計算リソースを用いてトレーニングを実行します。実行環境の主な選択肢は、LLMプロバイダのプラットフォームとローカル・クラウド環境の2種類です。
<トレーニング実行環境の比較>
| 環境の種類 | 特徴 | 主な用途 |
| プロバイダプラットフォーム | データアップロード後にコマンドを実行するだけで処理が始まる。GPU環境の構築が不要 | 手軽に始めたい場合 |
| ローカル・クラウド環境 | 自前のGPUを活用。高い柔軟性とカスタマイズ性がある | 大規模モデルの本格運用 |
トレーニング中は、検証データセットを用いて定期的にモデルの精度を確認します。損失関数の推移を観察し、検証データでの損失が上昇し始めた場合は過学習の兆候です。
過学習を検知した際は、アーリーストッピング(早期停止)を適用してトレーニングを中断します。処理時間は、データ量やモデルの規模に応じて、数分から数時間程度と幅があります。
余裕を持ったスケジューリングが、安定したトレーニング運用を支える前提条件の一つです。
5. 評価・デプロイと継続的な改善
トレーニングが完了したら、テストセットを用いてモデルの最終パフォーマンスを評価します。精度・適合率・再現率など、タスクに関連する評価指標を確認したうえで、実用水準への適合を判断する段階です。
<主な評価指標の例>
| 評価指標 | 内容 |
| 精度(Accuracy) | 全体の中で正解した割合 |
| 適合率(Precision) | 「正解」と予測した中で実際に正解だった割合 |
| 再現率(Recall) | 実際の正解の中で「正解」と予測できた割合 |
パフォーマンスが不十分な場合は、ハイパーパラメータの調整やデータセットの見直しが必要になります。別のファインチューニング手法への切り替えも、選択肢の一つです。
評価が完了したモデルは、アプリケーションやシステムにデプロイします。実運用後も、継続的なモニタリングが欠かせません。モデルの性能は時間の経過とともに劣化する現象があり、モデルドリフトと呼ばれています。
定期的な再トレーニングや、ユーザーフィードバックに基づく改善を継続的に実施することで、モデルの精度と信頼性を長期的に維持できます。
ファインチューニングで学習させるデータの例3選

ファインチューニングの効果は、学習させるデータの質と内容によって大きく左右されます。どのようなデータが追加学習に適しているかを把握することは、導入設計の精度を高めるうえで重要な前提条件です。
ここでは、ファインチューニングで学習させる社内非公開データ・専門分野データ・最新データという3種類の特性と活用方法を解説します。
社内に存在する非公開データ
社内の非公開データは、ファインチューニングで追加学習させる候補の中で最も優先度が高いデータ群です。
企業が独自に管理するデータは、インターネット上に公開されていないため、汎用LLMの事前学習データには含まれていません。社内固有の知識への対応力を持つAIを構築するには、追加学習が必要です。
<ファインチューニングに活用できる社内非公開データの例>
- 業務マニュアル・社内規定
- 顧客対応履歴・クレーム対応記録
- 社内FAQ・ナレッジベース
社内データを学習させることで、手続きや社内ルールに関する問い合わせへの的確な回答生成が可能になります。社内問い合わせ対応の効率化や、ナレッジ共有の促進という効果が見込めます。
一方、機密性の高い情報を含む可能性があるため、利用データの選定にはセキュリティ面での確認が欠かせません。クラウド型LLMを使用する場合は、学習データがサードパーティのリスクにさらされないよう、セキュアなインフラ上での実行が推奨されます。
専門性が高い分野のデータ
医療・法律・金融など専門性が高い分野のデータは、汎用LLMが苦手とする領域への対応力を高める学習素材として有効です。汎用LLMは専門分野について一定の知識を持っていますが、専門家水準の回答精度には至っていないケースが多くあります。
<専門分野別のファインチューニング学習データの例>
| 分野 | 主な学習データの例 |
| 医療 | 臨床データ・薬剤情報・診断事例 |
| 法律 | 判例・法令文書・契約書 |
| 金融 | 市場データ・規制文書・取引履歴 |
専門データでファインチューニングを実施することで、業界固有の用語や文脈を正確に理解したモデルを構築できます。専門家水準の情報提供が必要な場面への対応力向上も期待できるのが、専門データ活用の強みです。
ただし、専門データを扱う際は、用語の正確性とデータの信頼性の両方に注意が必要です。国内外で業界特化型LLMの開発が活発に進む中、専門データを活用したファインチューニングは、生成AI実用化の現実的な選択肢として定着しつつあります。
公開されたばかりの最新データ
公開されたばかりの最新データは、事前学習済みモデルの知識の時間的な限界を補う学習素材として機能します。LLMは事前学習時点までに収集されたデータをもとに構築されているため、事前学習後に公開された情報には対応できません。
最新のニュースや法改正情報、新製品の市場動向などについて質問しても、正確な回答を返せないケースが生じます。
<最新データの活用が特に有効なシーン>
- 法改正や規制変更など、時限的な情報への対応が必要な場面
- 最新の統計データや市場動向をもとにした分析業務
- 新製品・新サービスに関する問い合わせ対応
最新の公開データを使ったファインチューニングを定期的に実施することで、モデルの知識を常に最新の状態に保てます。更新前の古い情報を参照して誤った回答を生成するリスクも、継続的な追加学習によって低減できます。
情報の鮮度が求められるシステムや、リアルタイムの動向に基づいた分析が必要な用途では、最新データの継続的な学習が必要です。
ファインチューニングを行う際の注意点5つ

ファインチューニングを実務で活用するには、あらかじめリスクと制約を把握しておく必要があります。準備不足のまま実施すると、期待した精度が得られないだけでなく、コストや工数の無駄が生じるでしょう。ここでは、ファインチューニングの実施前に押さえておくべき5つの注意点を解説します。
過学習(オーバーフィッティング)のリスクがある
過学習とは、モデルがトレーニングデータに過度に適合し、未知のデータへの汎化性能が低下する現象です。ファインチューニングでは、事前学習時と比べて小規模なデータセットを使用するため、過学習が発生しやすい傾向があります。
少量のデータに過剰にフィッティングしたモデルは、実際の運用で期待した精度を発揮できなくなる恐れがあります。
<過学習を防ぐための主な対策>
- 学習データの多様性を確保し、偏りのないデータセットを構築する
- 正則化やドロップアウトなどを活用して、モデルの汎化性能を高める
- アーリーストッピングを設定し、トレーニングを適切なタイミングで停止する
- データ拡張により、学習データの実質的な量と多様性を増やす
検証データを用いた定期的なモニタリングは、過学習の早期発見に有効な手段の一つです。トレーニングの進捗を継続的に確認することで、汎化性能の低下を未然に防げます。
大規模モデルでは計算リソース・コストが増大する
大規模モデルをフルファインチューニングする際、高性能なGPU環境が必須になります。数億〜数十億個のパラメータを持つモデルの全パラメータを更新するには、重みだけの場合よりも12〜20倍のGPUメモリが必要とされています。
クラウドサービスを活用する場合、利用料金が大きく膨らむリスクも無視できません。
<計算コスト増大への主な対策>
- LoRAやQLoRAなどのPEFT手法を採用し、更新パラメータ数を大幅に絞り込む
- 軽量モデル(SLM)に特定タスク向けのファインチューニングを施し、コストを抑制する
- クラウドサービスのスポットインスタンスや従量課金プランを組み合わせて利用する
PEFT手法の採用により、計算量とメモリ使用量を大幅に削減できます。大規模モデルの導入を検討する場合、事前にコストシミュレーションを実施するのも準備の一つです。
学習データの質と量がモデル精度を左右する
ファインチューニングの成果は、学習データの品質と量に大きく依存します。ノイズや偏りを含むデータを使用すると、モデルの精度が低下します。誤った出力を生むリスクが高まるのも、問題の一つです。
データ量が不十分な場合、ファインチューニングの効果そのものが限定的になりがちです。対象タスクや領域の全体像を網羅できる量のデータは、最低限確保しておく必要があります。多様なバリエーションを用意できるほど、モデルの汎化性能は向上しやすくなります。
<学習データの品質を高めるための主な取り組み>
- 不正確な情報や重複データを取り除くデータクレンジングを丁寧に行う
- アノテーション(ラベル付け)には、ドメインの専門知識を持つ人材を関与させる
- 収集段階から目的に沿ったデータ設計を行い、ノイズの混入を最小化する
教師あり学習では、アノテーションの精度がモデルの出力品質を直接左右します。データ準備の段階に十分な工数を確保するのが、ファインチューニング全体の成果を高めるでしょう。
破滅的忘却によりベースモデルの知識が失われる
破滅的忘却(Catastrophic Forgetting)とは、ファインチューニングによって事前学習の知識がモデルから失われる現象です。フルファインチューニングでは全パラメータが更新されるため、汎用的な能力が低下するリスクが特に高くなります。
特定の専門分野に過度に特化させた結果、基本的な一般常識への回答品質が著しく劣化するケースがあります。
<破滅的忘却を軽減するための主な手法>
| 手法 | 概要 |
| PEFT(LoRAなど) | 更新範囲を限定し、事前学習の知識を保護する |
| EWC(弾性重み固定) | 重要パラメータの変更にペナルティを科し、知識消失を抑制する |
| ER(経験再生) | 事前学習時のデータを再利用し、既存知識の保持を促す |
学習率を低めに設定することも、破滅的忘却の抑制に有効な手段の一つです。事前学習で培われた汎用的な知識を意図的に保護する設計がなければ、モデルの実用性は大きく損なわれます。
継続的なメンテナンスと専門人材の確保が必要になる
ファインチューニング済みモデルは、デプロイ後も継続的なメンテナンスとアップデートが必要です。AI技術の進化は急速で、新しいアルゴリズムやデータの登場に応じてモデルの再調整が求められます。
外部環境の変化を見越した定期的な見直しを怠ると、モデルの精度が実用水準を下回るリスクは否定できません。
<継続的な運用で求められる主な対応>
- 定期的な再トレーニングとパフォーマンスモニタリングの実施
- モデルドリフト(性能の経時劣化)の早期検知と対処
- ファインチューニングに精通した専門人材の配置、または外部サポートの活用
社内に専門リソースが不十分な場合、外部の専門業者によるサポートを受けることも選択肢の一つです。
【FAQ】ファインチューニングに関するよくある質問

ファインチューニングの導入を検討する際、データ量やコスト、商用利用の可否など、実務的な疑問が生じやすい場面があります。ここでは、ファインチューニングに関するよくある5つの質問に回答します。
ファインチューニングに必要なデータ量の目安はどのくらいですか?
必要なデータ量は、対象タスクの複雑さやベースモデルの種類によって大きく異なります。OpenAIのガイドラインでは、GPT-3.5-turboのファインチューニングに最低10件のサンプルが必要とされています。
一般的に、50〜100件のトレーニングサンプルがあれば、明確な改善を確認できる水準です。ただし、タスクの難易度や求める精度によっては、数百〜数千件のデータが必要になる場合もあります。
重要なのは、データの量だけでなく質の高さです。少量でもタスクに直結した高品質なデータであれば、有意な効果が期待できます。一方、大量であっても、ノイズや偏りが多いデータでは精度向上につながりません。
<データ量の目安と対応方針>
| サンプル数 | 想定される効果 |
| 10〜49件 | 最低限の動作確認。精度向上は限定的 |
| 50〜100件 | 明確な改善が期待できる出発点 |
| 数百〜数千件 | 高難度タスクや高精度が求められる場合に必要 |
まず50件程度の丁寧に作成したサンプルで開始し、改善傾向を確認しながら段階的にデータを追加するアプローチが推奨されています。データ準備には工数とドメインの専門知識が求められるため、計画的な取り組みが欠かせません。
ファインチューニングとRAGはどちらを選ぶべきですか?
ファインチューニングとRAGの選択は、解決したい課題の性質によって判断します。モデルの振る舞いや応答スタイルを恒久的に変えたい場合や、専門用語・業界知識をモデルに内在化させたい場合には、ファインチューニングが適しています。
最新情報や頻繁に更新されるデータを扱いたい場合や、回答の出典を明示したい場合には、外部データベースを参照するRAGが有効です。
<目的別の選択基準>
| 目的 | 適した手法 |
| 応答スタイルや専門知識の内在化 | ファインチューニング |
| 最新情報への対応・出典の明示 | RAG |
| 出力の簡易な調整 | プロンプトエンジニアリング |
| 両方の課題を解決したい | ハイブリッド活用 |
実務での一般的な判断順序は、まずプロンプトエンジニアリングで対応できるかを検証することです。
外部知識の参照が必要であればRAGを選択し、モデル自体の能力を根本的に変えたい場合にファインチューニングを検討する流れが定着しています。両手法を組み合わせたハイブリッド活用も、検討しましょう。
ファインチューニングにGPUは必要ですか?
GPUが必要かどうかは、利用するプラットフォームとモデルの規模によって異なります。OpenAIなどのLLMプロバイダが提供するファインチューニング機能を利用する場合、GPU処理はプロバイダ側のサーバーで実行されます。
データをアップロードしてコマンドを実行するだけで処理が開始されるため、ユーザー自身がGPU環境を用意する必要はありません。オープンソースモデルをローカルや自社クラウド環境でファインチューニングする場合は、GPUが必要になります。
ただし、LoRAやQLoRAなどのPEFT手法を活用することで、比較的小規模なGPU環境でも大規模モデルのファインチューニングを実行できます。
<実行環境別のGPU要否>
| 実行環境 | GPU要否 | 特徴 |
| OpenAIなどのプロバイダプラットフォーム | 不要 | データ準備とコマンド実行のみで完結 |
| ローカル・自社クラウド環境 | 必要 | PEFT手法で小規模GPUでも対応可能 |
費用面では、プロバイダプラットフォームにはファインチューニング専用の課金体系が用意されています。自前のGPU環境構築とのコスト対効果を事前に比較したうえで、実行環境を選定しましょう。
ファインチューニングで生成した回答の商用利用は可能ですか?
ファインチューニング済みモデルの商用利用の可否は、ベースモデルのライセンス条件によって決まります。OpenAIのGPTシリーズでは、APIを通じて生成したコンテンツの商用利用が、利用規約の範囲内で認められています。
MetaのLlamaシリーズなど、商用利用可能なライセンスで提供されているオープンソースモデルも選択肢の一つです。ただし、モデルごとにライセンス条件が異なるため、個別の確認が必須です。
<商用利用前に確認すべき3つの項目>
- ベースモデルのライセンス条件(商用利用の許可範囲)
- 学習データの著作権や利用条件(無断使用による侵害リスク)
- 生成物の利用範囲(再配布・販売の可否)
ファインチューニングに使用する学習データの著作権にも注意が必要です。著作物を無断で学習データに含めた場合、生成結果が著作権侵害に該当するリスクがあります。商用利用を前提とする場合は、法務部門や専門家への事前相談が推奨されます
プログラミングの知識がなくてもファインチューニングはできますか?
プログラミングの知識がなくてもファインチューニングを実施できる環境は、近年急速に整ってきています。OpenAIのプラットフォームでは、管理画面上からデータのアップロードとファインチューニングの実行が可能です。
TensorFlowやPyTorchを用いた複雑なコーディングは不要で、操作の敷居は大幅に下がっています。Google AutoMLのようなノーコードツールでは、マウス操作だけでモデルの学習と評価を完結させられます。
<ノーコード・ローコードで活用できる主なツール>
| ツール | 特徴 |
| OpenAI Fine-tuning | 管理画面からデータ準備・実行が可能 |
| Google AutoML | ノーコードでモデルの学習・評価が完結 |
| Hugging Face AutoTrain | GUIベースでオープンソースモデルに対応 |
ツールの操作はプログラミング不要でも、効果的なファインチューニングには別の知識が求められます。学習データの設計・品質管理・ハイパーパラメータの基本的な理解・評価方法のリテラシーは、精度向上に直結します。
初回の導入時は、専門家のサポートを受けながら進めることで、失敗リスクを抑えられるでしょう。
まとめ
ファインチューニングは、AI活用を実務レベルで深化させるための具体的な手法として、多くの企業で導入が進んでいます。仕組みを正しく理解したうえで、目的・データ・手法の3点を適切に設計することが、高精度なモデルを効率的に構築する前提条件です。
導入後も継続的なモニタリングと改善を繰り返すことで、ファインチューニング済みモデルは実用的な価値を長期にわたって発揮し続けます。
過学習や破滅的忘却などのリスクを把握しながら、計画的に運用体制を整えるのが、長期的な成果につながります。AI活用を本格化させたい企業や担当者にとって、ファインチューニングは有力な選択肢でしょう。




